Karpathy《Software 3.0》逐段全译(基于 Latent Space 整理稿)
原始演讲:YC AI Startup School Keynote, 2025-06-17 译版底稿:Latent Space - Andrej Karpathy on Software 3.0(由 swyx 整理的带注释 transcript + 截图导读) 本译版定位:完整逐段翻译(配少量译注)。对应精读版
01-karpathy-software-3.0.md。格式说明:Latent Space 这篇是 swyx(Latent Space 主编)对 Karpathy 演讲做的带注释导读 + Karpathy 推文关联。它不是逐字 transcript,但完整覆盖了演讲的全部 6 个 Part 和所有关键金句。下面翻译同时包含 swyx 的导读文字和 Karpathy 的引语原话(在
>引用块里)。
译者前言
如果说前 4 篇是工程指南,Karpathy 这场演讲是世代纲领。他用一个钟头给整个软件行业重新画了三代:1.0 写代码 → 2.0 训神经网络 → 3.0 写 prompt。这套坐标系在他演讲后 4 个月内成为行业默认词汇,后来又被他自己升级成 “agentic engineering”(2026-04 Sequoia Ascent)。
下面是 Latent Space 整理稿的完整中文翻译。所有 🟢 译注: 是我加的,其余是原作者(swyx)的导读或 Karpathy 的引语。
Andrej Karpathy 谈 Software 3.0:AI 时代的软件
基于 Andrej 在 YC AI Startup School 2025 演讲的带注释截图与全 transcript
Part 0:Software 3.0 —— Prompt 现在就是程序
我们最早在 《Rise of the AI Engineer》 里讨论过 Software 3.0,但它其实是 Software 2.0 那篇文章 + “最火的新编程语言是英语” 的显然推论。
Andrej 最初在 Tesla 写 Software 2.0 那篇时,观察到 2.0 正在吃掉 1.0(神经网络逐步替代手写代码)。他现在又回来,为 Software 3.0 升级这个论述。
不再是修改 Software 2.0 的图,Andrej 这次发布了一张新图,展示 Software 1.0 / 2.0 / 3.0 的拼接共存。他强调:
“Software 3.0 is eating 1.0/2.0”(Software 3.0 正在蚕食 1.0 和 2.0)
“a huge amount of software will be rewritten”(大量软件将被重写)
Andrej 仍然聚焦在”prompt 即程序”。我们 在 2023 年有过轻微分歧,现在仍然有 —— “1+2=3” 的 Software 3.0 变体,正是过去几年 AI Engineer 远远跑赢 Prompt Engineer 的全部理由(并将继续如此)。
🟢 译注:这个三代分类法是这篇演讲最重要的认知贡献。它给整个行业提供了一个共享坐标系:讨论任何 AI 工具时,都可以问”这是 1.0 / 2.0 还是 3.0?”
Part 1:LLM 是新型计算机
LLM 像公共事业(Utilities)
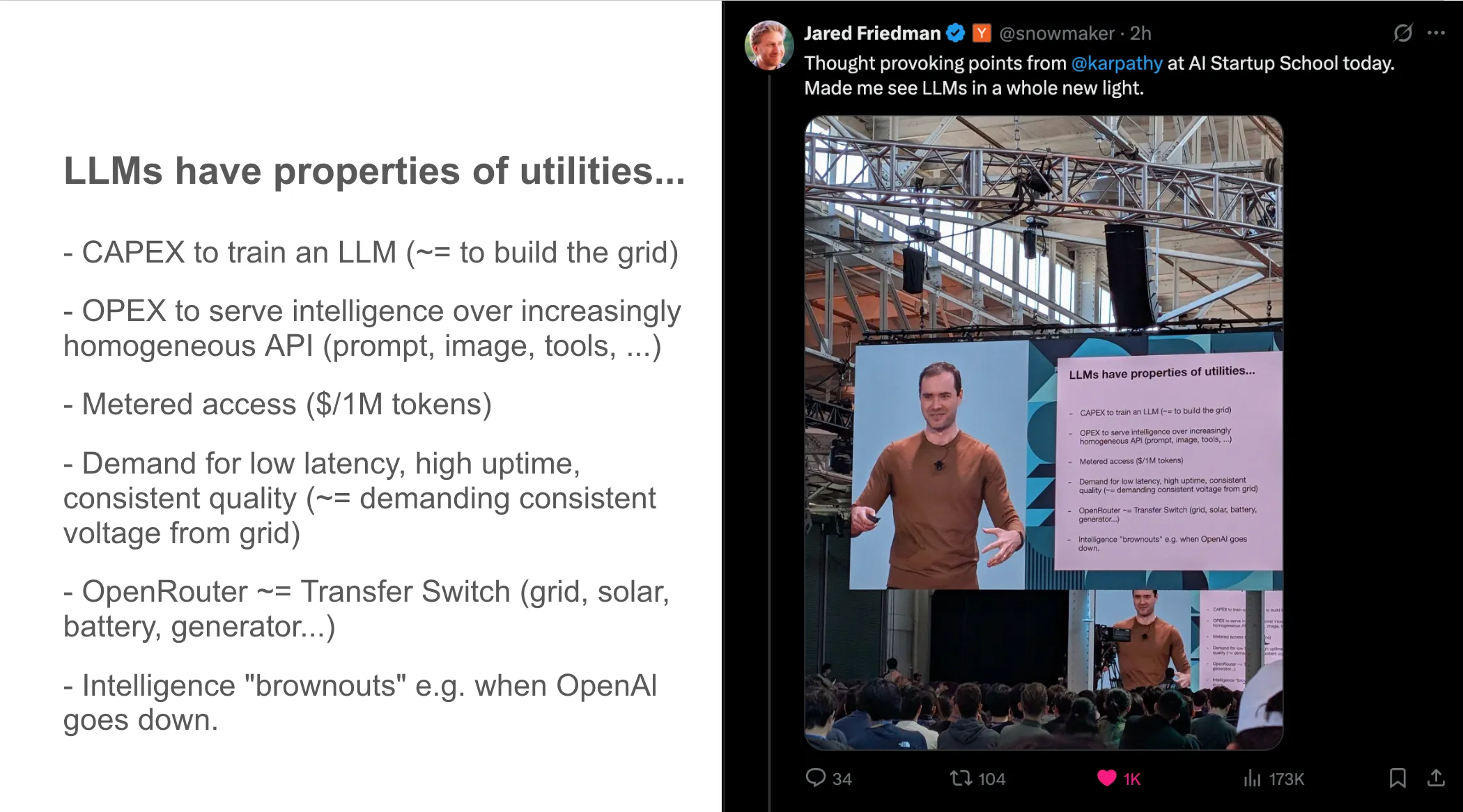
LLM 像电力、水、网络这种公共事业 —— 大部分使用者不需要自己造发电厂,只需要从插座取电。少数巨头建立基础设施(OpenAI、Anthropic、Google),其余人都是消费者。
LLM 像晶圆厂(Fabs)

像台积电:资本密集、技术密集,只有少数玩家能玩。基础模型训练需要的硬件投资量级跟建一座 fab 类似。
LLM 像操作系统(OSes)

LLM 是新一代 OS:
- CPU:模型本身
- 内存:context window
- 应用:agent 和 prompt 程序
- 你”安装”的不是软件,是 prompt
LLM 像分时主机(Timeshare Mainframes)

像 1960 年代的 mainframe —— 昂贵、稀缺、需要分时共享。但他在 《Power to the People》 里指出,LLM 也展示了与昂贵前沿技术常规扩散流向不同的反向模式:先到消费者手里,再到政府/公司。
我们离开云端走向 个人/私有 AI 时,Personal Computing v2 的迹象正在 Exolabs + Apple MLX 工作里出生。
Part 1 总结
LLM = utility + fab + OS + timeshare mainframe 的混合体,但走相反的扩散路径(消费者 → 公司,而不是公司 → 消费者)。
🟢 译注:Karpathy 用这四种比喻给 LLM 定位。这些比喻不是修辞 —— 它们决定了你怎么设计产品。把 LLM 当 utility = 你做应用;当 OS = 你做平台;当 timeshare mainframe = 你做基础设施服务。
Part 2:LLM 心理学
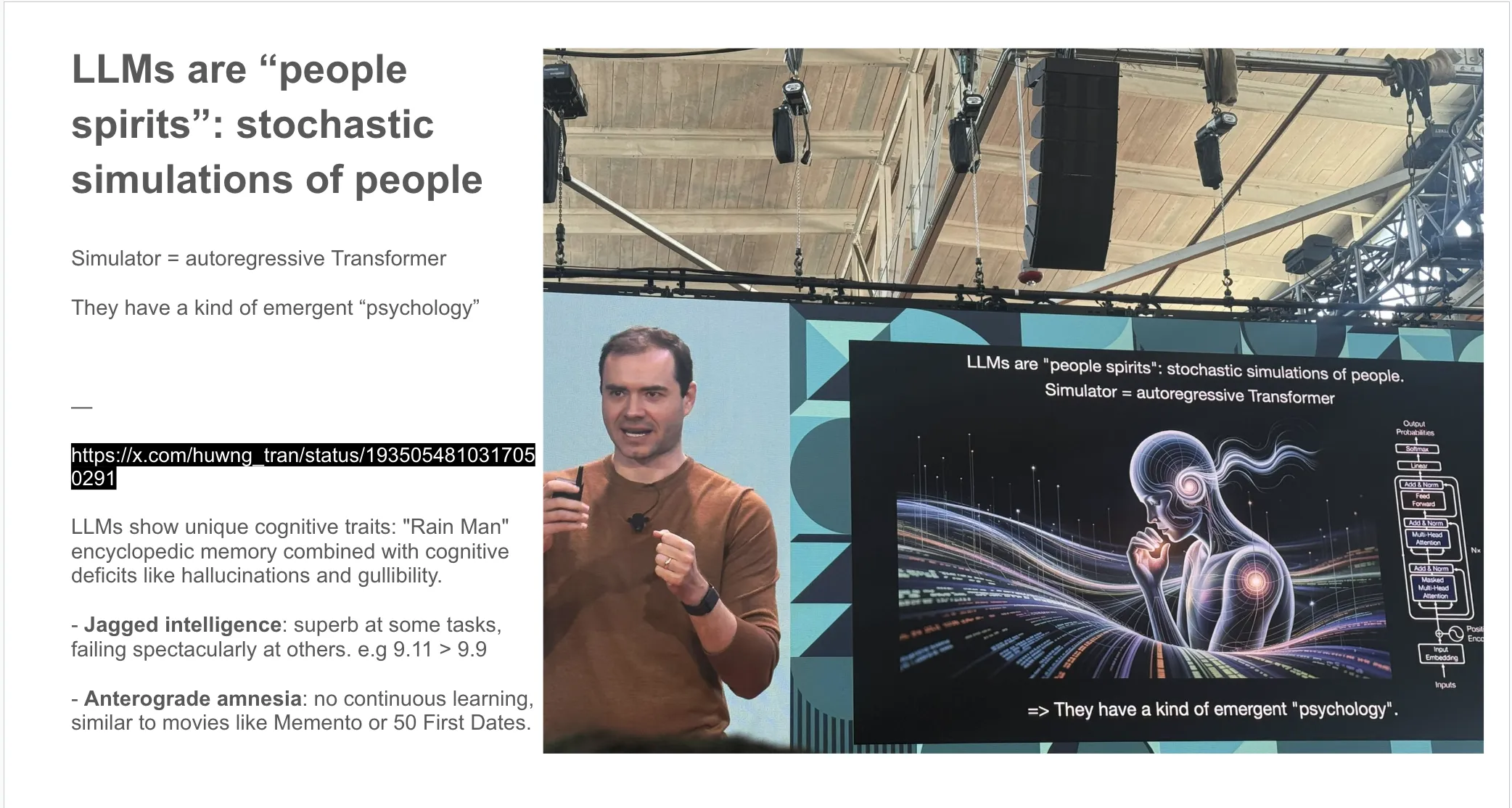
LLM 是”people spirits”:人的随机模拟,带着涌现出的”心理”。
“LLMs are ‘people spirits’: stochastic simulations of people, with a kind of emergent ‘psychology’.”
Andrej 突出了当前 LLM 模拟人的两个问题:
问题 1:Jagged Intelligence(参差智能)
(Karpathy 原话,2024-08-25 X)
我造了一个词来描述这个(奇怪、反直觉的)事实:SOTA LLM 既能完成极端令人印象深刻的任务(比如解决复杂数学问题),又同时在某些非常蠢的问题上挣扎。比如两天前 —— 9.11 和 9.9 哪个大?它答错了。
一些事情极其好用(以人类标准),一些事情灾难性失败(也以人类标准)。哪些是哪些不总是显然的,但你可以慢慢培养一点直觉。这跟人类不同 —— 人类大量知识和问题解决能力高度相关、从出生到成年线性一起改进。
我个人认为这些不是基础问题。它们要求堆栈各处更多工作,不止 scaling。我认为最大问题是当前缺乏”认知自我知识”(cognitive self-knowledge),这要求模型 post-training 阶段更复杂的方法,而不是”模仿人类标注员然后做大”这种朴素方案 —— 后者目前为止把我们带到了这里。
现在,这是要意识到的事,尤其在生产环境。用 LLM 做它擅长的任务,但留意 jagged edges,保持 human in the loop。
🟢 译注:“Jagged Intelligence”(参差智能) 这个词后来在 AI 圈广泛流传。它准确描述了 LLM 的核心特性:不是均匀变弱,是某些维度天才、某些维度幼稚园,且分布无规律。
问题 2:Anterograde Amnesia(顺行性失忆症)

(Karpathy 原话,2025-06-04 X)
我喜欢解释:LLM 有点像一个患顺行性失忆症的同事 —— 它们训练结束后不会巩固或建立长跑知识/专长,所有它们有的就是短期记忆(context window)。带着这种状况建关系(参考《初恋 50 次》)或工作(参考《Memento》)非常难。
(关于他认为缺失的”system prompt learning”范式)
我们至少缺一个 LLM 学习的主要范式。不知道叫什么 —— 可能叫 system prompt learning?
Pretraining 是为知识。 Finetuning(SL/RL)是为习惯性行为。
这两者都涉及参数变化,但人类的很多学习,感觉更像 system prompt 的变化。你遇到一个问题,搞清楚一些事,然后用相当显式的术语”记住”,以便下次。比如”看起来当我遇到这种和那种问题时,我应该试这种或那种方法”。它感觉更像给自己做笔记 —— 一种像 ChatGPT 的 “Memory” feature,但不是存每用户的随机事实,而是通用/全局的问题解决知识和策略。
LLM 字面上像 Memento 里那个人,只是我们还没给它们 scratchpad。注意 这个范式也极其更强、更数据高效 —— 因为知识引导的”复习”阶段是比奖励标量高得多维度的反馈通道。
……
在我看来这不是应该通过 RL 烧到权重里的问题解决知识 —— 至少不是立即/排他地。它当然不应该来自人类工程师手写的 system prompt。它应该来自 system prompt learning —— 跟 RL 设置相似,除了学习算法(edit vs gradient descent)。LLM 系统提示的一大段可以通过 system prompt learning 写出来,它会看起来像 LLM 自己给自己写一本”如何解决问题的书”。如果这能行,就是一个新的、强大的学习范式。
🟢 译注:“LLM 是患顺行性失忆症的同事” 这个隐喻深入到产品设计层面。它告诉你:所有要 LLM 跨 session 工作的产品,都需要重新设计 memory 机制 —— 因为它本质上记不住任何事。这正是后来 Anthropic harness engineering 解决的核心问题。
Part 2 总结
LLM 是 stochastic simulations of people。它们有 jagged intelligence 和顺行性失忆。设计产品时必须为这两点工程化解决方案。
Part 3:部分自主性(Partial Autonomy)

我们喜欢钢铁侠战衣的类比 —— 战衣以两种有用方式扩展我们:
- Augmentation(增强):给用户力量、工具、传感器、信息
- Autonomy(自主):战衣很多时候有自己的想法 —— 不被提示就采取行动
怎么设计跟随这两种模式的 AI 产品?
Part 3a:自主滑块(Autonomy Sliders)
Autonomy Slider 是个重要概念,让我们根据上下文选择自主程度。例子:
- Cursor:Tab → cmd+K → Cmd+L → Cmd+I(agent mode)
- Perplexity:search → research → deep research
- Tesla Autopilot:Level 1 到 Level 4



🟢 译注:这是这场演讲对产品经理最直接的礼物。所有让用户”全自动 or 全手动”二选一的 AI 产品,都设计错了。用户的信任度需要被产品尊重。
Part 3b:人类-AI 生成-验证循环
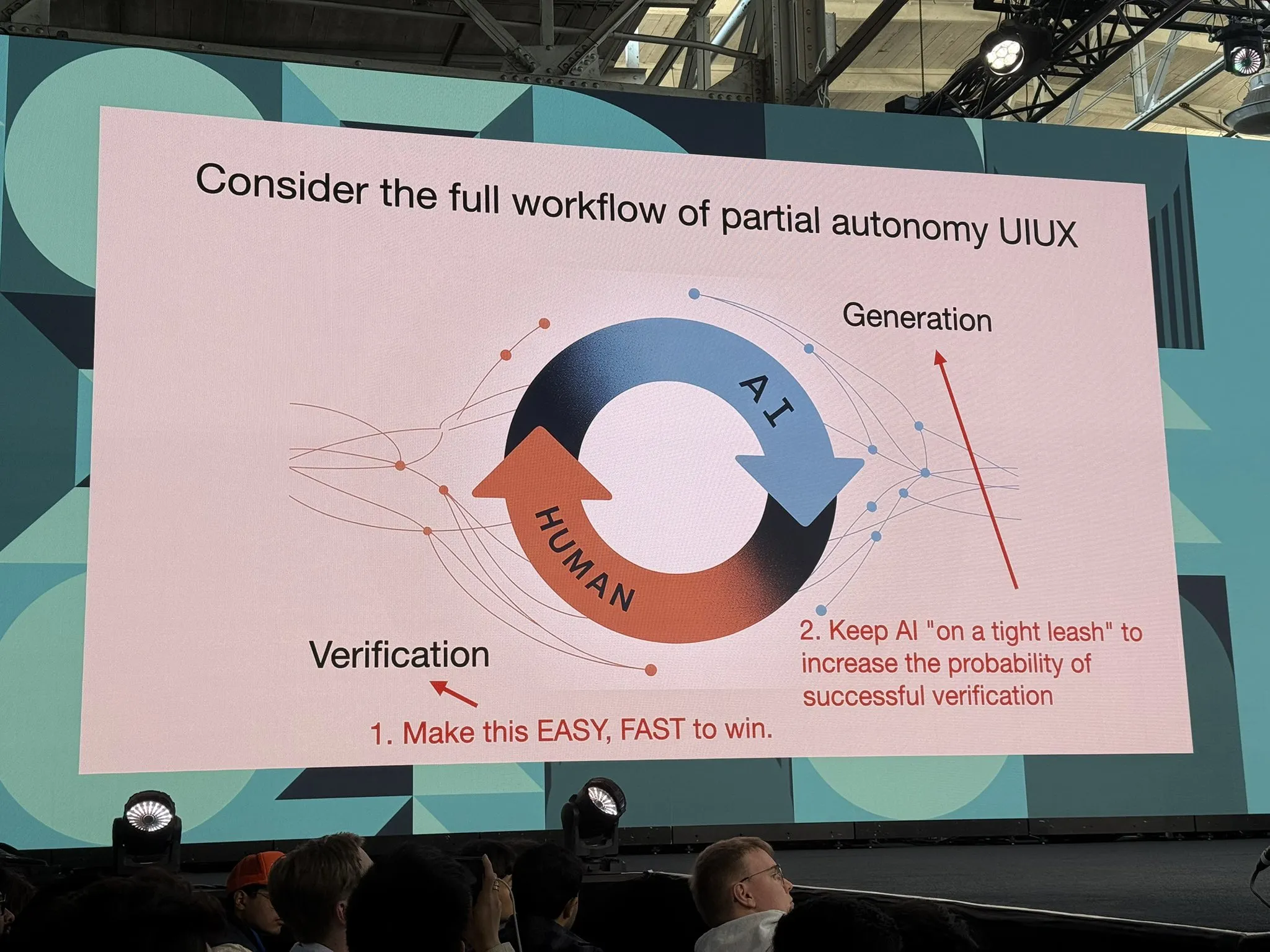
在生成 ↔ 验证循环里,我们需要 partial autonomy 的完整工作流 —— 循环越快越好:
- 改进验证:让它容易、快速、易胜
- 改进生成:把 AI 拴紧(keep AI on tight leash)
Part 3c:演示与产品的鸿沟
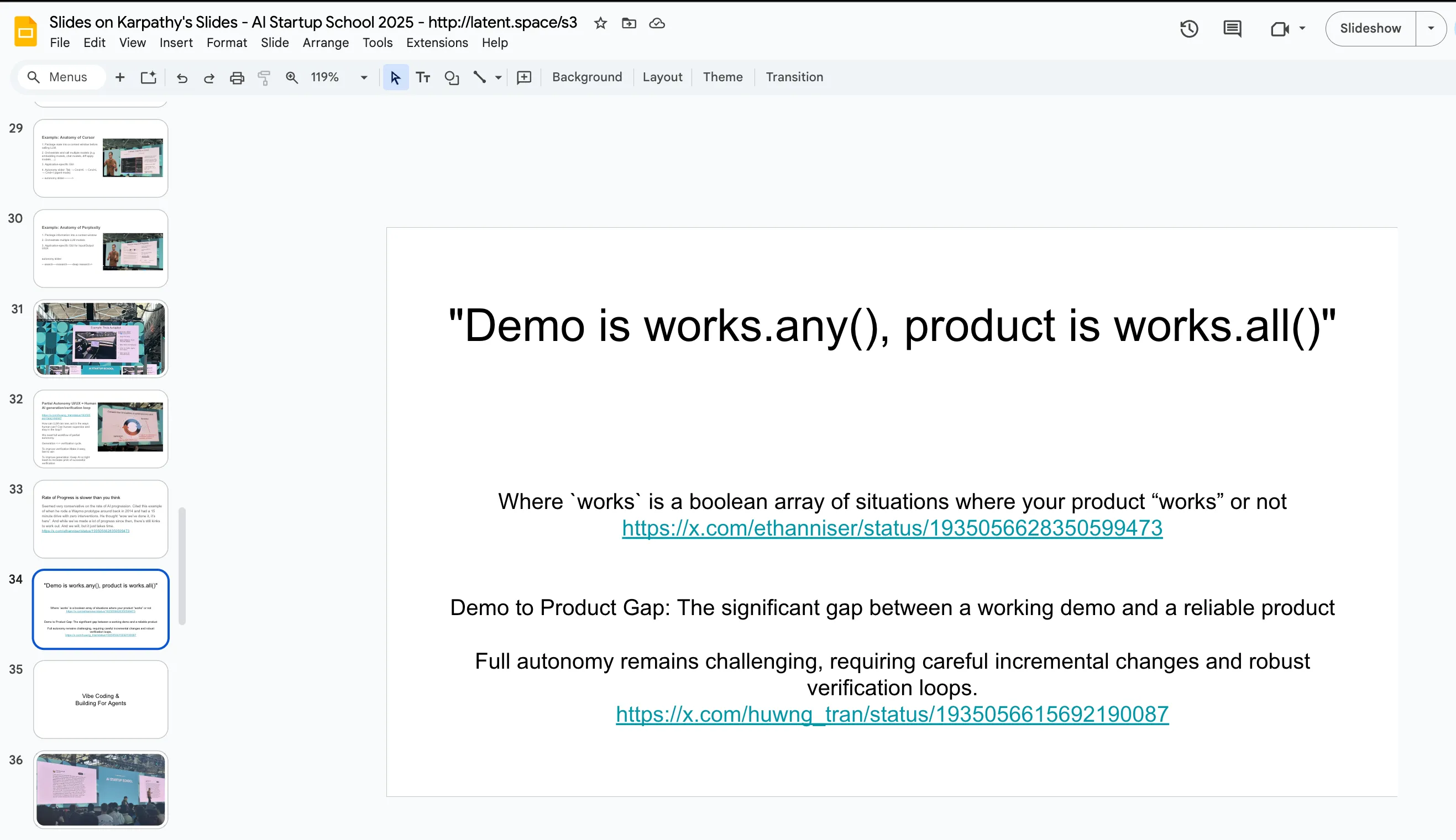
为什么我们需要 PARTIAL 自主性? —— 因为工作的演示和可靠的产品之间仍有显著鸿沟。
他 回忆 2014 年坐 Waymo 原型车零接管,以为自动驾驶”已经到了”…… 但还有大量东西要解决。11 年过去,FSD 仍不够好。
“Demo is
works.any(), product isworks.all().” (演示是”任何一次能跑就行”,产品是”每一次都得能跑”。)
🟢 译注:这一句是给所有 AI 创业者的冷水。从”任意一次能跑”到”每次都能跑”,通常比前 90% 的工作长几个数量级。所有”我们 AI demo 看起来已经做完了”的公司:你才走完前 10% 的工作量。
Part 4:Vibe Coding

那条催生千家创业公司的推文:
“The hottest new programming language is English.” (最火的新编程语言是英语。)
—— 现在 有它自己的 Wikipedia 页面了!
然而,仍然有大量遗留问题。Karpathy 在 vibe coding MenuGen 时发现 —— AI 加速效果在本地代码跑起来后不久就消失了。
2025 年建 web app 的现实 —— 是一团碎片化的服务,设计目标是让 webdev 专家保住饭碗,而不是对 AI 友好。
可怜的 Clerk 拿到了负面提名;Vercel 的 @leerob 拿到了正面提名 —— 在他们的文档分别是为人类还是为 agent 调优这件事上。
🟢 译注:Karpathy 这场演讲让
llms.txt这种 agent-friendly 文档格式开始普及。Vercel 的胜利不在产品,而在文档对 agent 的可解析性。
Part 5:为 Agent 构建产品

底线是 —— 工具制造者必须意识到”有了一类新的数字信息消费者/操作者”:
- Humans(用 GUI)
- Computers(用 API)
- NEW: Agents —— 是计算机,但又像人类
具体来说:llms.txt 之所以有用,是因为 HTML 对 LLM 不太可解析。

他还点名了 “Context builders” 比如 Gitingest 和 Cognition 的 DeepWiki —— 我们曾在一期 lightning pod 里 profile 过它们。
🟢 译注:“Agents 是新的第三类信息消费者” 这个观察后来变成 SaaS / 开发工具产品经理最重要的设计原则。未来 30% 以上的访问可能来自 agent —— 你的产品如果只为人设计,就是给自己关门。
收束 / 总结
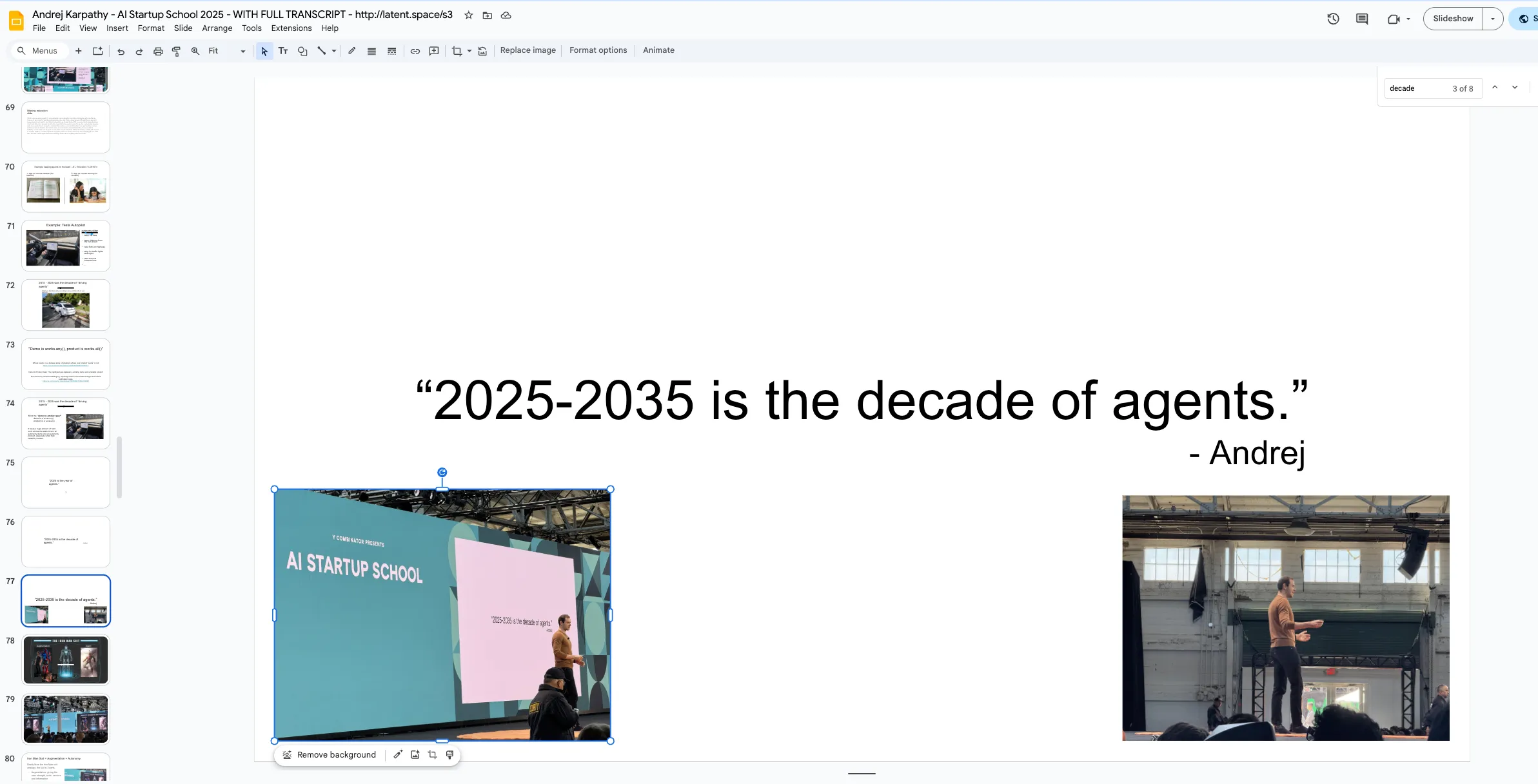
This is the Decade of Agents.(这是 Agent 的十年。)
少一些 AGI 2027 的炫目演示但根本不工作。
多一些:
- partial autonomy(部分自主)
- 自定义 GUI
- autonomy sliders(自主滑块)
记住:
- Software 3.0 正在蚕食 Software 1/2
- 它们作为 Utility / Fab / OS 的特性,会决定它们的命运
- 改进 generator-verifier 循环
- BUILD FOR AGENTS 🤖(为 Agent 构建)
译者总评
如果你只从这场演讲带走 5 件事:
- Software 3.0 已经在蚕食一切 —— 你写的不再是代码,是 prompt 是 spec 是 context
- 设计自主滑块,不要二选一 —— 用户的信任度需要被产品尊重
- Demo 是
works.any(), 产品是works.all()—— 别被 demo 骗 - LLM 是患顺行性失忆症的人形随机模拟 —— 用这个心智模型重新设计你的产品
- 为 agent 构建你的产品 —— 它即将是你最重要的用户
这场演讲本身就是一个时代的标志,但那个时代正在以季度为单位被取代。Karpathy 在 2026-04 Sequoia Ascent 已经把 “vibe coding” 升级为 “agentic engineering” —— 因为 LLM 已经强到 “vibe coding” 都过时了。
但坐标系仍然有效:Software 3.0、autonomy slider、works.any() vs works.all()、为 agent 构建 —— 这些都没过期。
🔗 调研来源(可校验)
见 01-karpathy-software-3.0.md 末尾的”调研来源”段落。本文与 01 互为对照。
额外说明 —— Latent Space 这一篇导读的归属:
- swyx(Shawn Wang)是 Latent Space 主编,也是 Software 3.0 / AI Engineer 早期推动者
- 他这篇是 付费订阅 Latent Space 后可看完整版 的”带注释 transcript”,免费版只到 “Closing/Recap”
- 我用的是免费版可见部分(已包含全部 Part 0-5 的核心论点),付费段是完整 slides 而非文字