Anthropic《Building Effective Agents》逐段全译
原文:anthropic.com/research/building-effective-agents 作者:Erik Schluntz, Barry Zhang(Anthropic 应用工程团队) 原发布:2024-12-19 本译版定位:完整逐段翻译(配少量译注)。对应精读版
02-anthropic-building-effective-agents.md。
译者前言
Anthropic 这篇是整个 agentic coding 领域引用最广的工程纲领。它的特别之处在于:它是 Anthropic 自家工程师跟数十个团队一起建 agent 之后写出来的总结,不是营销稿,不是研究报告,就是工程笔记。下面是逐段中文翻译。所有 🟢 译注: 是我加的。
构造有效的 Agent(Building Effective Agents)
发布于 2024-12-19
我们跟跨行业的数十个团队一起建 LLM agent。一致地,最成功的实现都用了简单、可组合的模式,而不是复杂的框架。
过去一年,我们和数十个跨行业的团队一起建大语言模型(LLM)agent。一致地,最成功的实现都没用复杂框架或专门的库。它们用的是简单、可组合的模式。
这篇博客分享我们从客户合作和自己造 agent 中学到的东西,给开发者关于如何造有效 agent 的实用建议。
什么是 Agent?
“Agent” 可以有多种定义。一些客户把 agent 定义为完全自主的系统,长时间独立运行,使用各种工具完成复杂任务。另一些人用这个词描述遵循预定义工作流的更指令性实现。
在 Anthropic,我们把所有这些变体归类为 agentic systems,但在 workflow 和 agent 之间画了一条重要的架构区分线:
- Workflow 是 LLM 和工具被预定义代码路径编排的系统
- Agent 是 LLM 动态指挥自己的过程和工具使用、保持对”如何完成任务”的控制权的系统
下面我们详细探讨这两种 agentic system。在附录 1(“实践中的 Agent”)里,我们描述了客户在两个领域用这类系统找到了特别价值。
🟢 译注:这条 workflow vs agent 的区分线是这篇文章最重要的贡献。99% 的”AI agent”项目其实是 workflow,这不是缺点,是优点 —— 它更可控、更便宜、更可调试。
何时(以及何时不)用 Agent
用 LLM 建应用时,我们建议先找最简单的方案,只在需要时增加复杂度。这可能意味着根本不建 agentic 系统。Agentic 系统通常用更高的延迟和成本换更好的任务表现 —— 你应该考虑这种 trade-off 何时合理。
当复杂度确实必要时:
- Workflow 给定义清楚的任务提供可预测性和一致性
- Agent 是更好的选择 —— 当灵活性和模型驱动的决策在规模上需要时
对许多应用来说,优化单次 LLM 调用 + retrieval + in-context examples 通常就够了。
🟢 译注:这一段是这篇的”反 hype 灵魂”。Anthropic 自家工程师在劝你别建 agent,这在 SDK 公司满天飞的环境里极其稀缺。
何时和如何用框架
有许多框架让 agentic 系统更容易实现:
- Claude Agent SDK
- Strands Agents SDK by AWS
- Rivet —— 拖拽式 GUI LLM 工作流构建器
- Vellum —— 另一个 GUI 工具,构建和测试复杂工作流
这些框架通过简化标准低层任务(调 LLM、定义和解析工具、串调用)让你更容易开始。然而,它们经常带来额外的抽象层,可能模糊底层 prompt 和响应,让调试更难。它们也可能让你在更简单方案足够时,被诱惑加复杂度。
我们建议开发者从直接用 LLM API 开始 —— 许多模式可以用几行代码实现。如果你用框架,确保你理解底层代码。对底层假设错误是客户错误的常见来源。
参考我们的 cookbook 看一些示例实现。
🟢 译注:这是 Anthropic 给”框架不要乱用”的官方背书。两年后 Armin Ronacher 跟 Dex Horthy 反复印证这个观点。
积木、Workflow、Agent
这一节,我们探索我们在生产中见过的 agentic 系统常见模式。我们从基础积木 —— 增强型 LLM 开始,逐步增加复杂度,从简单组合的 workflow 到自主 agent。
积木:增强型 LLM(Augmented LLM)
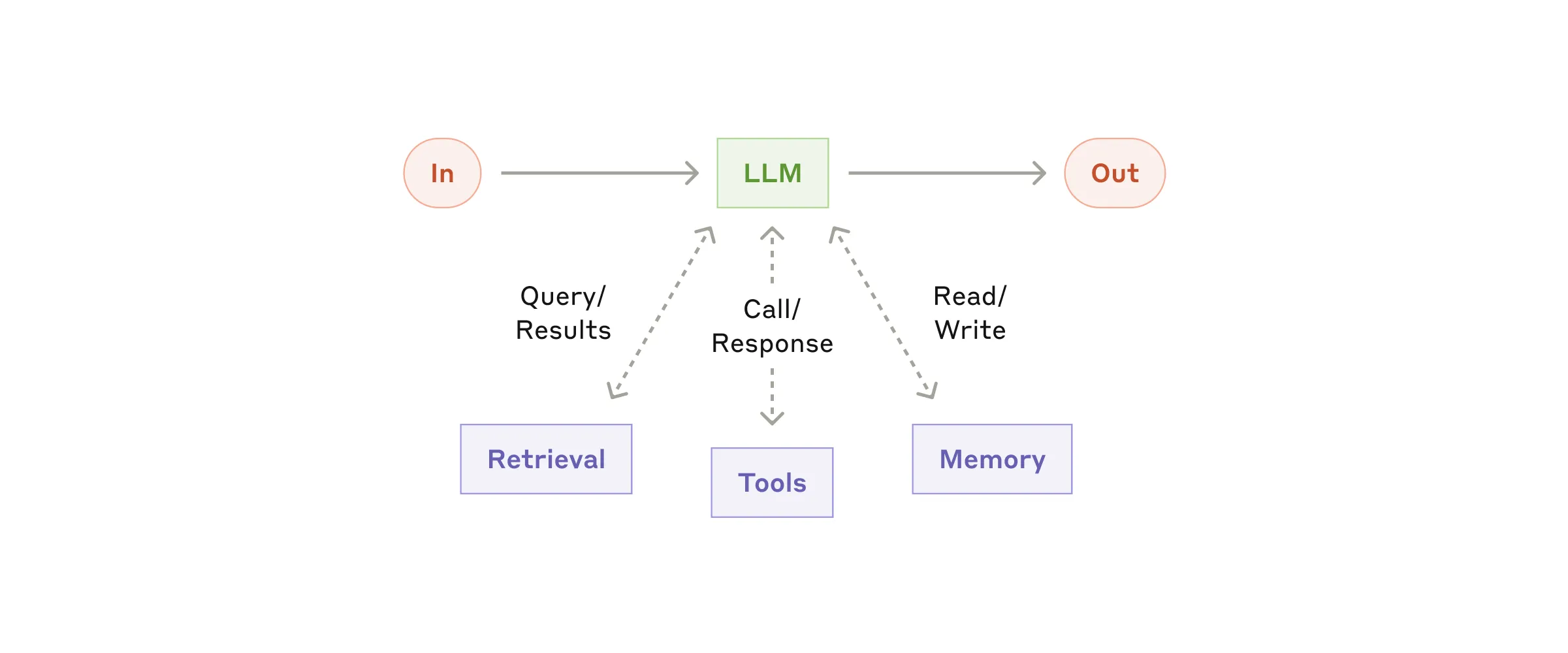
agentic 系统的基本积木是用增强能力扩展过的 LLM:
- Retrieval(检索)
- Tools(工具)
- Memory(记忆)
我们当前的模型可以主动使用这些能力 —— 自己生成搜索查询、选择合适工具、决定保留什么信息。
我们建议聚焦实现的两个关键方面:
- 把这些能力针对你的具体用例定制
- 确保它们给 LLM 提供简单、文档完备的接口
虽然有许多方式实现这些增强,一个方式是通过我们最近发布的 Model Context Protocol (MCP),允许开发者通过简单 client 实现 集成不断增长的第三方工具生态。
接下来全文,我们假设每次 LLM 调用都有这些增强能力。
Workflow #1:Prompt Chaining(提示链)
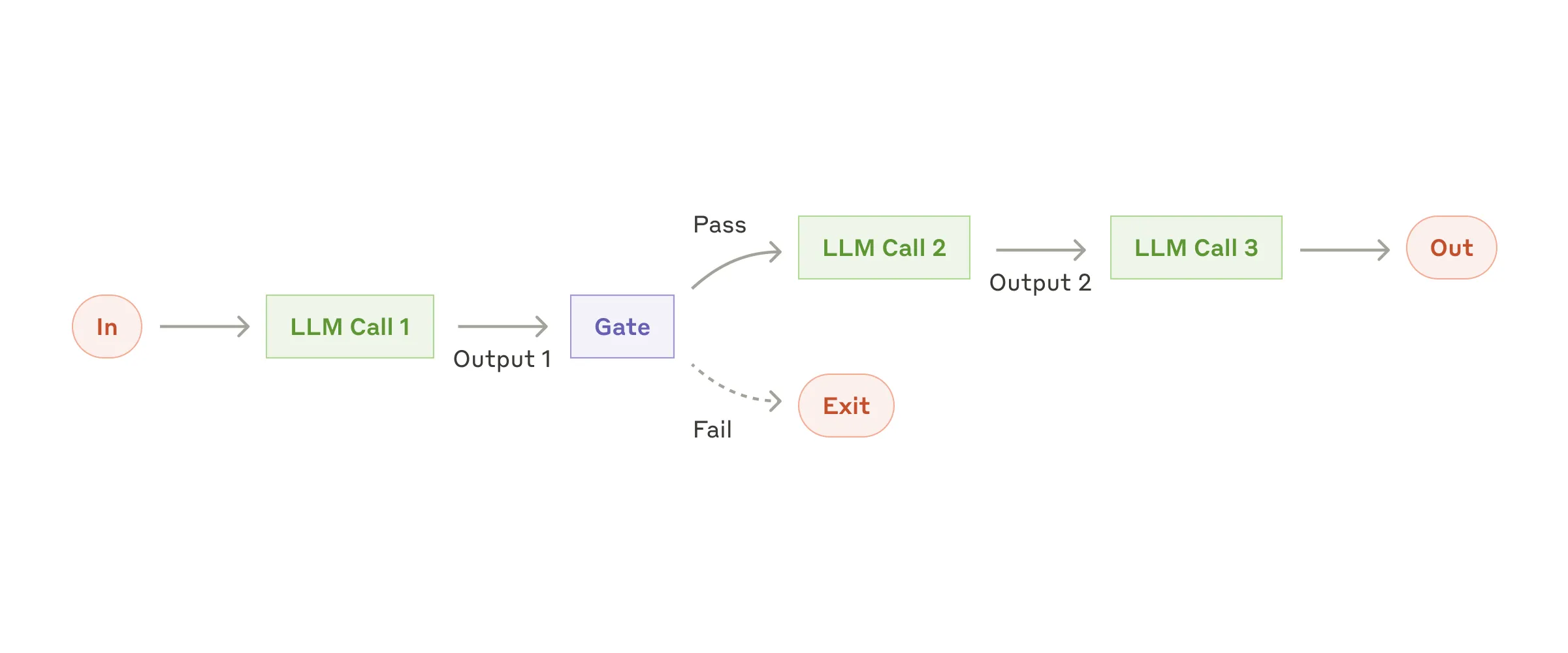
Prompt chaining 把一个任务分解为一系列步骤,每次 LLM 调用处理上一次的输出。你可以在任何中间步骤加程序化检查(“gate”),确保流程仍在正轨。
何时用这个 workflow:任务可以被容易、清晰地分解为固定子任务。主要目标是用延迟换更高准确率 —— 让每次 LLM 调用更容易。
Prompt chaining 有用的例子:
- 生成营销文案,然后翻译成另一种语言
- 写文档大纲,检查大纲符合某些标准,然后基于大纲写文档
Workflow #2:Routing(路由)
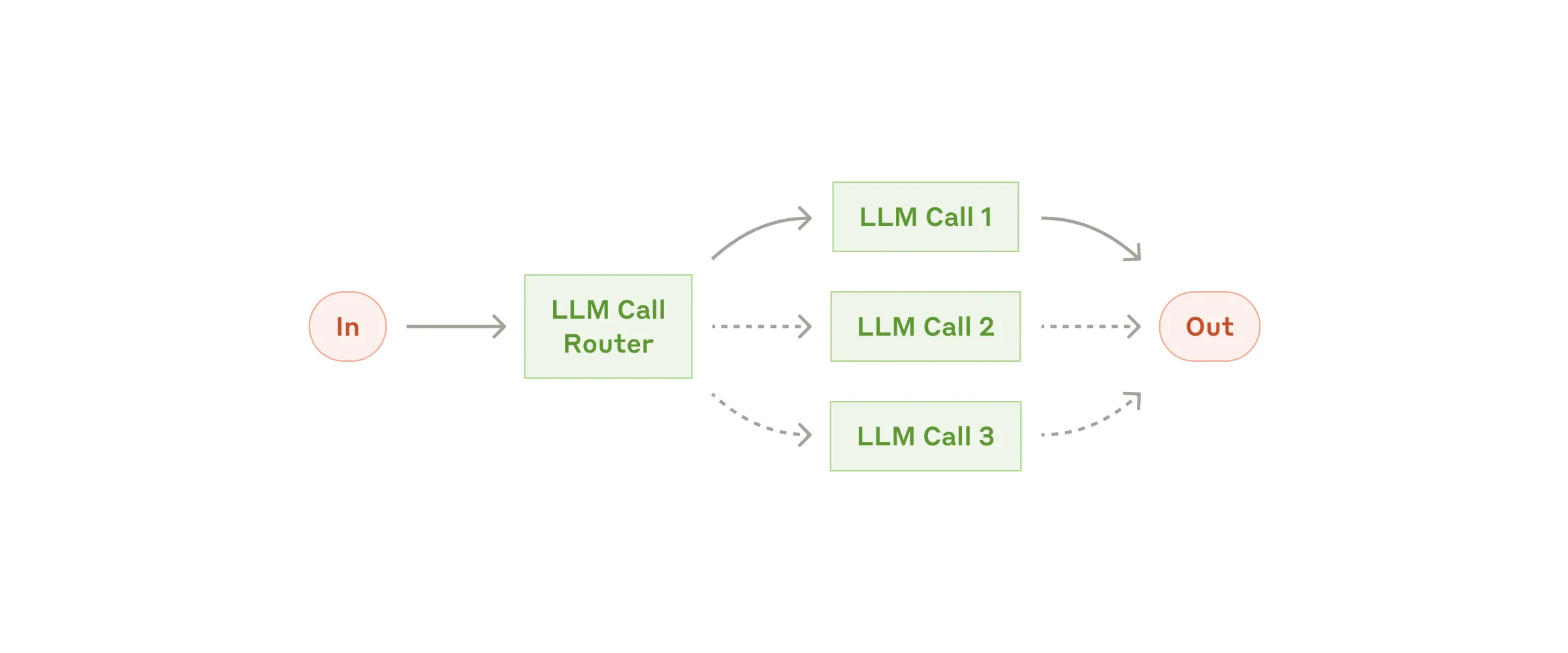
Routing 把输入分类,导向到一个专门的后续任务。这个 workflow 允许关注点分离,构建更专门的 prompt。没有这个 workflow,优化一种输入会损害另一种输入的表现。
何时用这个 workflow:复杂任务存在不同类别,分开处理更好,且分类可以被准确处理(LLM 或更传统的分类模型/算法)。
Routing 有用的例子:
- 把不同类型的客服查询(一般问题、退款请求、技术支持)导向不同的下游流程、prompt 和工具
- 把简单/常见问题路由到更小、成本更低的模型如 Claude Haiku 4.5,把困难/不寻常的问题路由到更强的模型如 Claude Sonnet 4.5,优化最佳表现
Workflow #3:Parallelization(并行化)
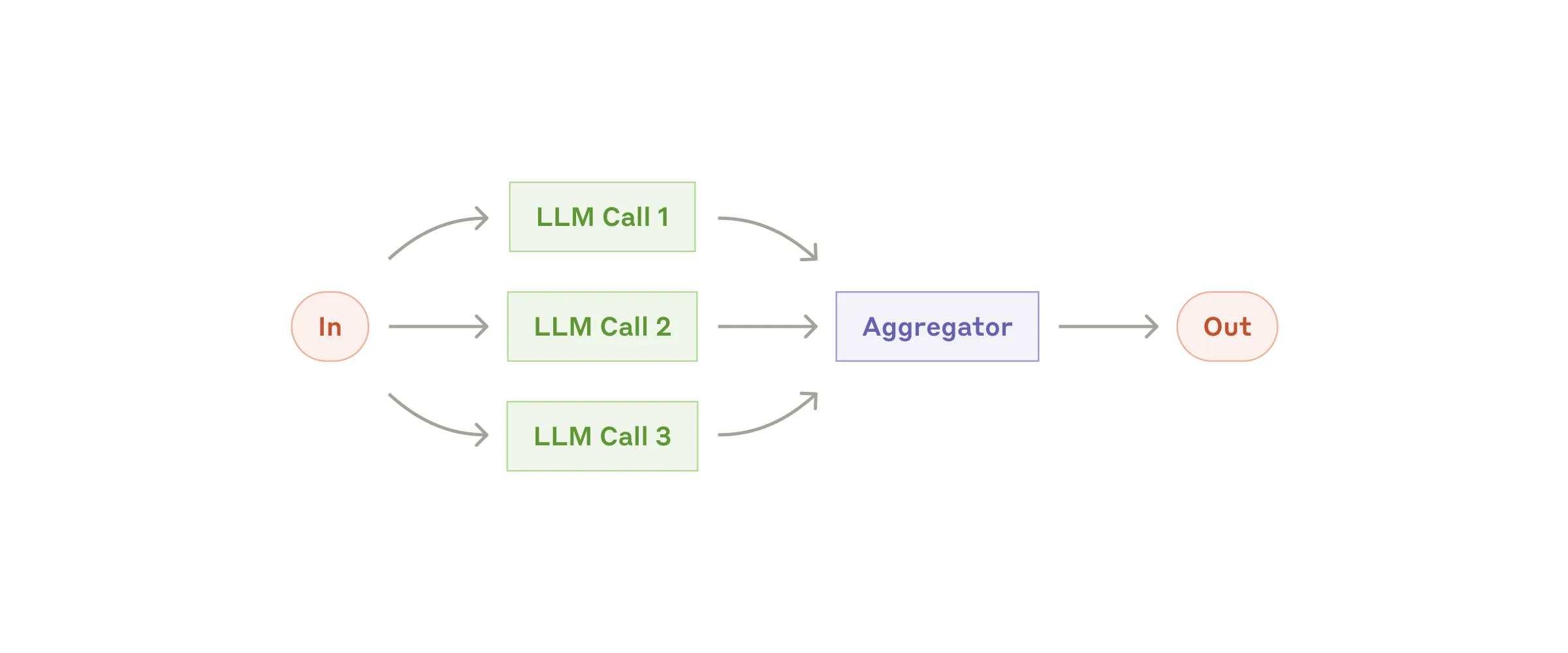
LLM 有时可以并行处理一个任务,然后程序化聚合输出。Parallelization 这个 workflow 表现为两种关键变体:
- Sectioning(分段):把任务分成独立子任务,并行跑
- Voting(投票):把同一任务跑多次,得到多种输出
何时用这个 workflow:
- 当被分的子任务可以并行加速时
- 当多视角或多次尝试需要更高置信度时
- 对有多个考虑维度的复杂任务,LLM 通常在每个考虑被一个独立 LLM 调用处理时表现更好(每个方面都能得到聚焦关注)
Parallelization 有用的例子:
-
Sectioning:
- 实现护栏 —— 一个模型实例处理用户查询,另一个筛查不当内容或请求。这通常比让同一个 LLM 调用同时处理护栏和核心响应表现更好
- 自动化 eval LLM 表现 —— 每次 LLM 调用评估给定 prompt 上模型表现的不同方面
-
Voting:
- 评审一段代码漏洞 —— 几个不同 prompt 都评审,发现问题就标记
- 评估某段内容是否不当 —— 多个 prompt 评估不同方面,或要求不同投票阈值平衡假阳性和假阴性
Workflow #4:Orchestrator-Workers(编排器-工人)
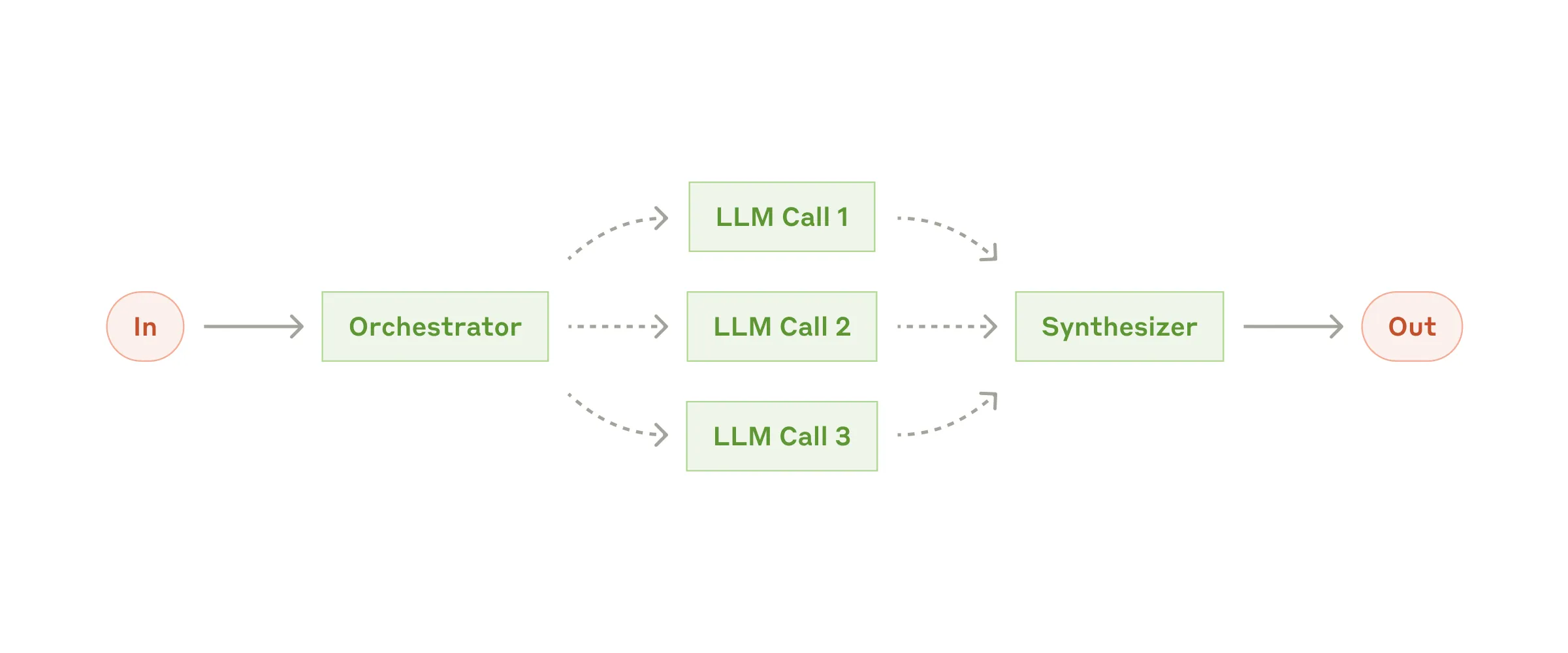
在 orchestrator-workers workflow 里,一个中央 LLM 动态分解任务,委托给工人 LLM,合成它们的结果。
何时用这个 workflow:复杂任务你无法预测需要的子任务(比如编程,需要改的文件数量和每个文件改动的性质,可能取决于任务)。虽然拓扑上跟 parallelization 相似,但关键区别是它的灵活性 —— 子任务不是预定义的,是 orchestrator 基于具体输入决定的。
Orchestrator-workers 有用的例子:
- 每次都对多个文件做复杂改动的编程产品
- 涉及从多个源收集和分析信息的搜索任务
🟢 译注:Claude Code 的 subagent 机制就是这个 pattern 的实现。理解了这个,你就理解了为什么 Geoffrey Huntley 的 Ralph Loop 强调”主 context 当调度器,让 subagent 干昂贵活”。
Workflow #5:Evaluator-Optimizer(评估器-优化器)
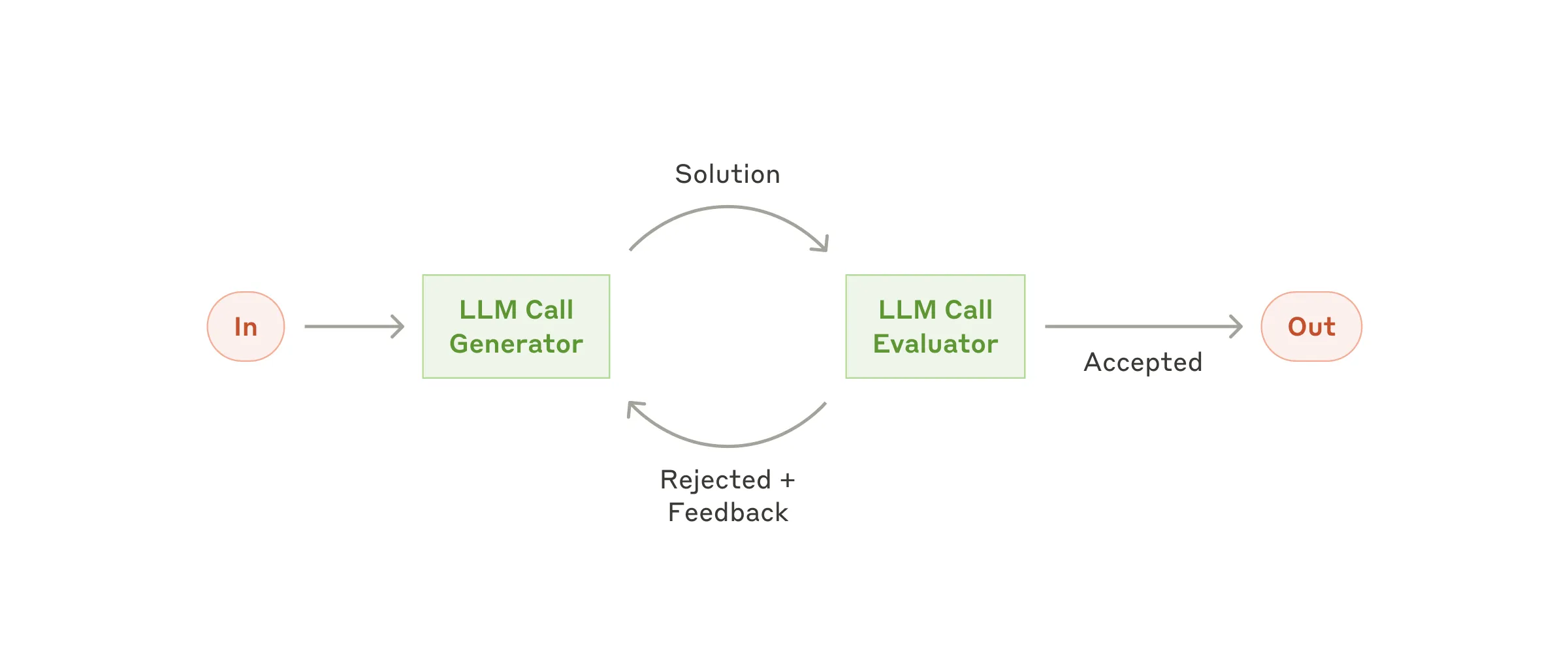
在 evaluator-optimizer workflow 里,一个 LLM 调用生成响应,而另一个在循环里提供评估和反馈。
何时用这个 workflow:特别有效当我们有清晰评估标准、且迭代精炼提供可量化价值时。两个适配的标志:
- 当人类清晰说出反馈时,LLM 响应能可观地改进
- LLM 自己也能提供这种反馈
这类似于人类作家产出精炼文档的迭代写作过程。
Evaluator-optimizer 有用的例子:
- 文学翻译 —— 译者 LLM 一开始可能抓不住的细微差别,评估 LLM 能给出有用的批评
- 复杂搜索任务,需要多轮搜索和分析收集全面信息,评估器决定是否需要进一步搜索
🟢 译注:这就是 Ralph Loop 的祖宗。Ralph 把 evaluator 简化为”测试通过 + git commit”,生成器是 Claude,这是这个 pattern 的极简实现。
Agents
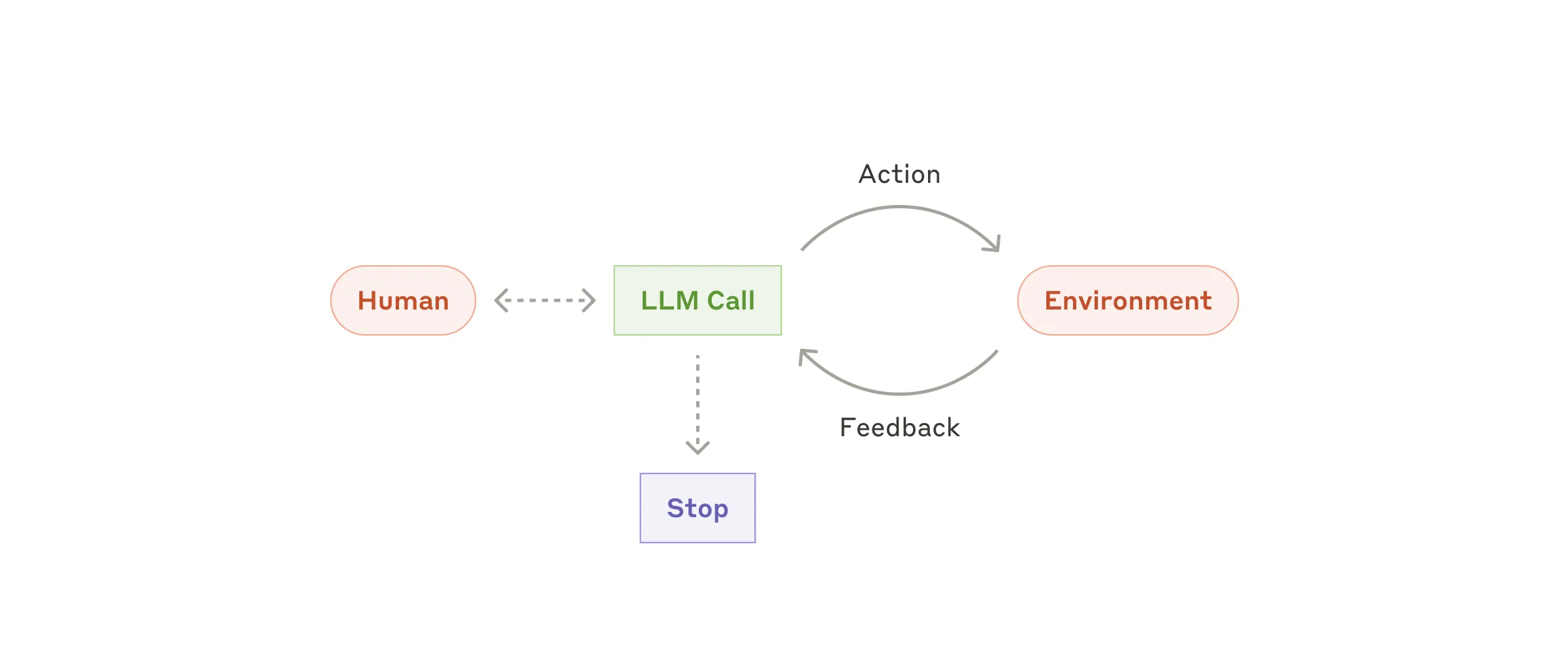
Agent 在生产中正在浮现 —— 因为 LLM 在关键能力上成熟了:理解复杂输入、推理和规划、可靠使用工具、从错误中恢复。
Agent 工作流:
- 从人类用户的命令或互动讨论开始
- 任务清晰后,agent 独立规划和操作,可能回到人类那里要更多信息或判断
- 执行中,关键是 agent 在每一步从环境获得”地面真相”(比如工具调用结果或代码执行)来评估进度
- Agent 可以在检查点暂停等人类反馈,或遇到阻塞时暂停
- 任务通常在完成时终止,但通常也包含停止条件(比如最大迭代数)来保持控制
Agent 可以处理复杂任务,但实现往往直接。它们通常就是 LLM 在循环里基于环境反馈使用工具。所以精心和清晰地设计工具集和它们的文档至关重要。我们在附录 2(“Prompt Engineering Your Tools”)扩展工具开发的最佳实践。
何时用 agent:用于开放性问题,难以或不可能预测需要的步骤数,且不能硬编码固定路径。LLM 可能跑很多轮,你必须对它的决策有一定信任。Agent 的自主性使它们适合在受信环境里规模化任务。
Agent 的自主性意味着更高成本和复合错误的可能。我们建议在沙箱环境里大量测试,加上合适的护栏。
Agent 有用的例子(来自我们自己的实现):
- SWE-bench 任务 编程 agent,基于任务描述对多文件做改动
- 我们的 “computer use” 参考实现,Claude 用电脑完成任务
组合和定制这些模式
这些积木不是规定性的。它们是开发者可以塑造和组合以适应不同用例的常见模式。成功的关键 —— 跟任何 LLM 特性一样 —— 是测量表现并迭代实现。
重申:你应该只在复杂度可观地改善结果时增加它。
总结
在 LLM 领域,成功不是建最复杂的系统。是建对你需求对的系统。
从简单 prompt 开始,用全面评估优化,只在简单方案不够时加多步 agentic 系统。
实现 agent 时,我们试图遵循三个核心原则:
- 保持 agent 设计的简单性(Maintain simplicity)
- 优先透明 —— 显式展示 agent 的规划步骤(Prioritize transparency)
- 精心打造 agent-计算机界面(ACI) —— 通过彻底的工具文档和测试(Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing)
框架可以帮你快速开始,但移到生产时,不要犹豫减少抽象层、用基础组件构建。遵循这些原则,你能造出不仅强大,而且可靠、可维护、被用户信任的 agent。
致谢
写作:Erik S. 和 Barry Zhang。本工作借鉴了我们在 Anthropic 造 agent 的经验,以及客户分享的宝贵洞察。
附录 1:实践中的 Agent
我们和客户的工作发现了 AI agent 两个特别有前景的应用,展示了上面讨论模式的实用价值。这两个应用都说明 agent 在哪种任务上加最大价值 —— 同时需要对话和动作、有清晰成功标准、能形成反馈循环、整合有意义的人类监督的任务。
A. 客户支持
客户支持结合熟悉的聊天界面与通过工具集成增强的能力。这是更开放的 agent 的天然契合,因为:
- 支持互动自然遵循对话流,同时需要访问外部信息和动作
- 工具可以集成拉取客户数据、订单历史、知识库文章
- 行动如发退款或更新工单可以程序化处理
- 成功可以通过用户定义的解决方案被清晰测量
几个公司通过基于使用的定价模型(只在成功解决时收费)证明了这个方法的可行性,显示对它们 agent 有效性的信心。
B. 编程 Agent
软件开发空间对 LLM 特性显示了惊人潜力,能力从代码补全演进到自主问题解决。Agent 在这里特别有效,因为:
- 代码方案可以通过自动化测试验证
- Agent 可以用测试结果作为反馈迭代方案
- 问题空间定义清晰、结构化
- 输出质量可以被客观测量
在我们自己的实现里,agent 现在可以基于 PR 描述,在 SWE-bench Verified benchmark 上解决真实 GitHub issue。然而,虽然自动化测试帮助验证功能,人类评审仍然对确保方案符合更宽泛的系统需求至关重要。
附录 2:为你的工具做 prompt engineering
不管你建什么 agentic 系统,工具大概率是你 agent 的重要部分。工具 通过在我们 API 里指定它们的精确结构和定义,让 Claude 能与外部服务和 API 交互。Claude 响应时,如果它计划调用工具,会在 API 响应里包含一个 tool use block。
工具定义和规格应该跟你整体 prompt 一样获得 prompt engineering 关注。这个简短附录里,我们描述如何为你的工具做 prompt engineering。
通常有几种方式指定同一个动作。比如,你可以通过写 diff 指定文件编辑,或通过重写整个文件。对于结构化输出,你可以在 markdown 或 JSON 里返回代码。在软件工程里,这种差别是表面的,可以无损地从一种转成另一种。
然而,某些格式比其它格式对 LLM 来说写起来困难得多。
- 写 diff 需要知道在新代码写之前 chunk header 里有多少行变化
- 在 JSON 里写代码(对比 markdown)需要额外转义换行和引号
我们对决定工具格式的建议:
- 给模型足够 token 来”思考”,在它写到死胡同前
- 保持格式接近模型在互联网文本里自然见过的样子
- 确保没有格式”开销”,比如必须保持准确计算几千行代码,或必须 string-escape 它写的任何代码
一个经验法则:想想人机界面(HCI)花了多少精力,计划在 agent-计算机界面(ACI)上投入同等精力。下面是一些做法的思考:
- 把自己放到模型的位置。基于描述和参数,这个工具怎么用是显然的吗?还是你需要仔细想?如果是后者,模型大概率也是。好的工具定义经常包含示例用法、边界情况、输入格式要求、与其它工具的清晰边界。
- 怎么改参数名或描述让事情更显然? 想想这是给团队里初级开发者写很棒的 docstring。当用许多相似工具时这特别重要。
- 测试模型怎么用你的工具:在我们 workbench 里跑许多示例输入,看模型犯什么错,迭代。
- Poka-yoke(防错)你的工具。改参数让出错变难。
为我们的 SWE-bench agent 建造时,我们实际上花在优化工具上的时间比花在整体 prompt 上的时间还多。比如,我们发现模型在 agent 离开根目录后会用相对路径出错。修复方式 —— 改工具,总是要求绝对路径 —— 我们发现模型用这方法零失误。
🟢 译注:最后这一段值得反复读。“花在优化工具上的时间比花在整体 prompt 上的时间还多” —— 这是大多数人完全反直觉的事实。如果你正在建 agent,从今天起把”调 prompt”和”调工具”的时间比例倒过来。
译者总评
这篇是反 hype 的杰作。Anthropic 自家工程师出来说:大多数你听到的”agent”,其实是 workflow,而且这没毛病。
如果你只从这篇带走 3 件:
- 能用单次 LLM 调用解决的,不要用 workflow;能用 workflow 解决的,不要用 agent
- Workflow 有 5 种 pattern(prompt chaining / routing / parallelization / orchestrator-workers / evaluator-optimizer)—— 记住它们,这是 agent 工程的入门词汇
- 优化工具(ACI)比优化 prompt 重要 —— 这一条值得纹身
5 种 workflow 在后续生态里的对应:
- Evaluator-optimizer = Ralph Loop 的祖宗
- Orchestrator-workers = Claude Code subagent 的祖宗
- Routing = 现代多模型路由(LiteLLM、Portkey)的祖宗
- Parallelization (sectioning) = 现代 fan-out 实现的祖宗
- Prompt chaining = LangChain 命名的来源
🔗 调研来源(可校验)
见 02-anthropic-building-effective-agents.md 末尾的”调研来源”段落。本文与 02 互为对照。