Dex Horthy《12-Factor Agents》逐段全译
原文 GitHub:humanlayer/12-factor-agents 作者:Dex Horthy(HumanLayer 创始人) License:Code 使用 Apache 2.0;Content 使用 CC BY-SA 4.0(可署名+相同方式分享自由翻译/再创作) 本译版定位:完整逐段翻译(README + 12 条因素详细文 + 译注)。对应精读版
03-dex-horthy-12-factor-agents.md。
译者前言
这是这个系列里版权最自由的一篇 —— 原作者明确选了 CC BY-SA 4.0,只要署名 + 相同方式开放,翻译/再创作都被祝福。这也是为什么这一篇我能直接逐字全译。
12-Factor 致敬 Heroku 的 12-Factor App,作者声称它是”用大白话写给那些试图造生产级 agent 但又不想被框架绑死的工程师”。如果你打算自己造 agent,这是 90% 失败模式的预防书。
12-Factor Agents —— 造可靠 LLM 应用的原则
致敬 12 Factor Apps。本项目源代码公开在 https://github.com/humanlayer/12-factor-agents,作者欢迎反馈和贡献。
💡 提示:
- 错过了 AI Engineer 世界博览会?在这里看演讲
- 想找 Context Engineering?直接跳到第 3 条因素
你好,我是 Dex。我已经在 AI agent 这件事上折腾了一段时间。
我试过市面上每一个 agent 框架 —— 从那些即插即用的 crew/langchain,到所谓的”极简” smolagents,到所谓”生产级”的 langgraph、griptape 等。
我跟很多很厉害的创始人聊过,YC 内外都有,他们都在用 AI 造令人印象深刻的东西。他们大多数都在自己撸技术栈。我没怎么见过框架在生产 customer-facing agent 里被用。
我惊讶地发现:市面上自称”AI Agent”的产品,大部分并不那么 agentic。它们大部分是确定性代码,在恰当的位置撒入 LLM 步骤,把体验做得真的有魔法感。
Agent —— 至少好的那些 —— 不走 “这是你的 prompt,这是一袋工具,循环到达成目标” 那种模式。相反,它们主体就是软件。
所以我开始问:
我们能用什么原则,造出真正能交到生产客户手上的 LLM 软件?
欢迎来到 12-Factor Agents。
🟢 译注:Dex 这个开场拳是这一篇的灵魂。“agentic 不是优点,实用才是” —— 这句话他说得不直接,但全篇暗示。
12 条因素简表
详细解读在下面,这里先列出来。
- Natural Language to Tool Calls(自然语言转工具调用)
- Own your prompts(掌握自己的 prompt)
- Own your context window(掌握自己的 context window)
- Tools are just structured outputs(工具就是结构化输出)
- Unify execution state and business state(统一执行状态与业务状态)
- Launch/Pause/Resume with simple APIs(用简单 API 实现启动/暂停/恢复)
- Contact humans with tool calls(用工具调用联系人)
- Own your control flow(掌握自己的控制流)
- Compact Errors into Context Window(把错误压缩进 context window)
- Small, Focused Agents(小而专注的 agent)
- Trigger from anywhere, meet users where they are(任何地方都能触发,在用户在的地方接住他们)
- Make your agent a stateless reducer(让 agent 变成无状态归约函数)
即使 LLM 继续指数级变强,仍会有核心的工程技巧让 LLM 软件更可靠、更可扩展、更易维护。
我们怎么走到这里
Agent 的承诺
我们会大量讨论有向图 (DG) 和无环有向图 (DAG)。先说一句,软件就是个有向图 —— 这就是为什么我们曾经用流程图来表示程序。
大约 20 年前,我们开始看到 DAG 编排器流行起来 —— Airflow、Prefect 这些经典的,以及一些前辈和后来者(dagster、inngest、windmill)。这些都遵循同样的图模式,但加了可观测性、模块化、重试、管理等好处。
Agent 的最大承诺(这话不是我先说的,但这是我学习 agent 时最大的收获):你可以把 DAG 扔了。不再需要软件工程师为每一步、每一个 edge case 写代码 —— 你可以给 agent 一个目标和一组转换,让 LLM 实时决定走哪条路。
承诺是:你写更少的软件 —— 你只给 LLM 图的”边”,让它自己决定”节点”。你能从错误里恢复,你能写更少的代码,你可能会发现 LLM 找到了新的解法。
Agent 是循环
不过,事实证明这并不完全行得通。
让我们再深一步 —— agent 是个 3 步循环:
- LLM 决定下一步,输出结构化 JSON(tool calling)
- 确定性代码执行这个工具调用
- 结果被追加到 context window
- 重复直到下一步被判定为”done”
initial_event = {"message": "..."}
context = [initial_event]
while True:
next_step = await llm.determine_next_step(context)
context.append(next_step)
if (next_step.intent === "done"):
return next_step.final_answer
result = await execute_step(next_step)
context.append(result)我们的初始 context 就是一个起始事件(可能是用户消息、cron 触发、webhook 等),我们让 LLM 选择下一步(工具)或决定我们已经完成。
为什么需要 12-Factor Agents?
事实是,这种纯 agent 方式不像我们希望的那样有效。
我在建 HumanLayer 的过程中,至少跟 100 位 SaaS 创始人聊过(大部分是技术型创始人)。他们的旅程通常是这样:
- 决定要造一个 agent
- 产品设计、UX 映射、决定要解决什么问题
- 想快,所以抓一个
$FRAMEWORK开始建 - 做到 70-80% 质量
- 意识到 80% 对大多数 customer-facing 功能不够好
- 意识到要超过 80% 必须反向工程框架、prompt、流程等
- 从头重写
🟢 译注:这个 7 步死亡循环,是这一篇被引用最多的部分。“70-80% → 推倒重来”已经成为 agent 圈的口头禅,跟 Anthropic 那篇”workflow vs agent”分类法并列被引用。
设计模式胜过框架
通过翻看几百个 AI 库 + 跟数十位创始人合作,我的直觉是:
- 有一些核心原则让 agent 变好
- 全押一个框架,做出来本质上是 greenfield 重写,可能反而适得其反
- 这些原则你会得到大部分(如果用框架)
- 但是 —— 我见过的最快让生产级 AI 软件到达客户手中的方式,是从 agent 建造里取小的、模块化的概念,塞进你已有的产品
- 这些模块化概念任何熟练的软件工程师都能定义和应用,即使他没 AI 背景
我见过让生产级 AI 软件最快到客户手里的方式,是从 agent 建造里取小的、模块化的概念,塞进你已有的产品
12 条因素详解
Factor 1 —— 自然语言转工具调用
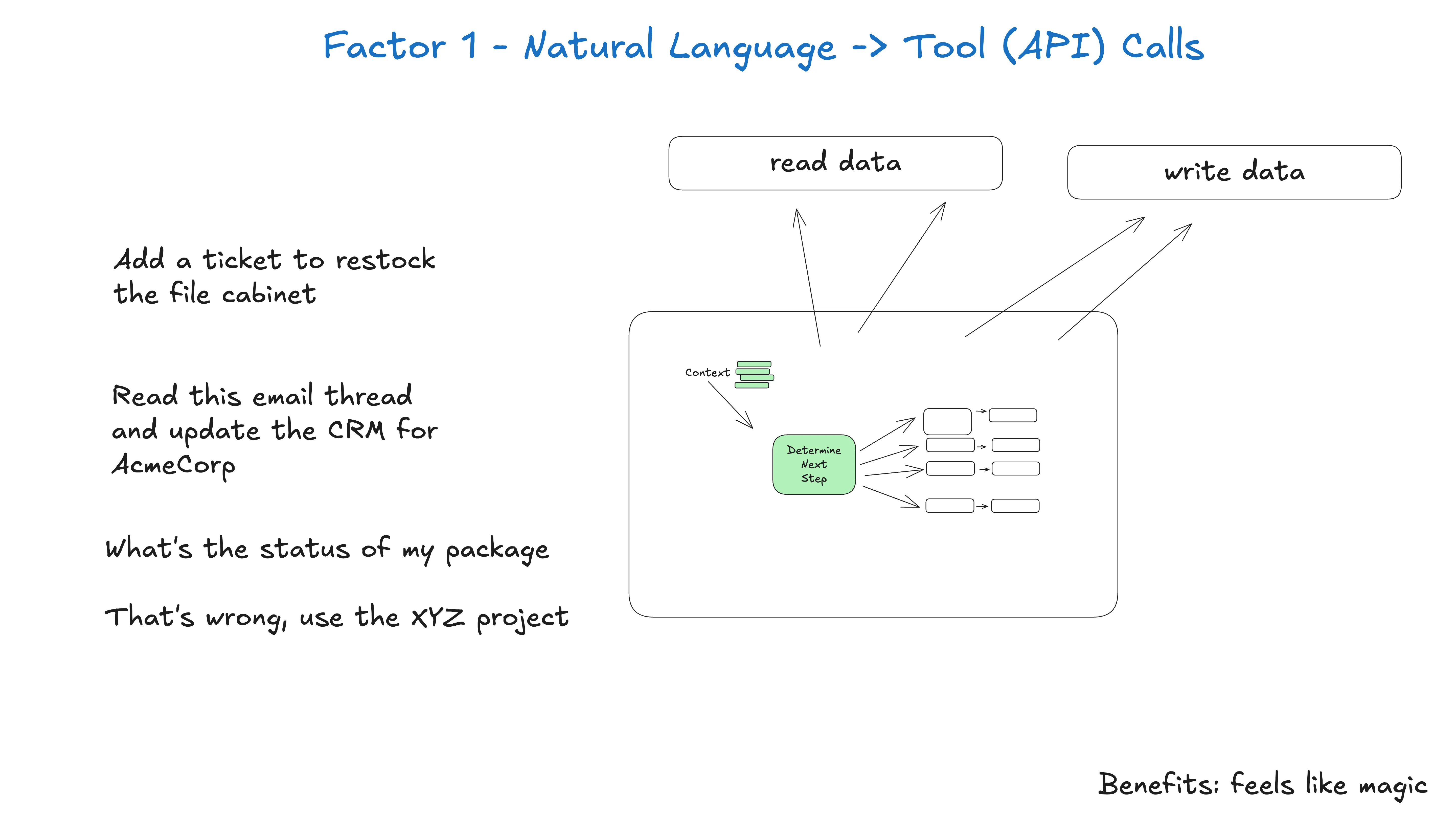
agent 建造里最常见的模式之一,是把自然语言转成结构化工具调用。
这个模式应用到原子粒度,就是把这样的一句话:
“你能创建一个 $750 的支付链接给 Terri 吗?用于赞助二月份的 AI tinkerers meetup。”
转成描述 Stripe API 调用的结构化对象:
{
"function": {
"name": "create_payment_link",
"parameters": {
"amount": 750,
"customer": "cust_128934ddasf9",
"product": "prod_8675309",
"price": "prc_09874329fds",
"quantity": 1,
"memo": "..."
}
}
}从这里开始,确定性代码就可以接手并做点什么。
nextStep = await llm.determineNextStep(
"create a payment link for $750 to Jeff for sponsoring the february AI tinkerers meetup"
)
if nextStep.function == 'create_payment_link':
stripe.paymentlinks.create(nextStep.parameters)
elif nextStep.function == 'something_else':
pass
else: # 模型调了我们不认识的工具
pass🟢 译注:Factor 1 是其它所有 factor 的基础假设。LLM 的核心价值不是对话,是把人话翻译成结构化操作。
Factor 2 —— 掌握自己的 prompt

不要把 prompt engineering 外包给框架。
有些框架提供”黑盒”式的接口:
agent = Agent(
role="...",
goal="...",
personality="...",
tools=[tool1, tool2, tool3]
)这对开始项目很好,但之后很难调 —— 你常常得反向工程才能把对的 token 喂进模型。
你应该把 prompt 当作一等代码:
function DetermineNextStep(thread: string) -> DoneForNow | ListGitTags | DeployBackend | DeployFrontend | RequestMoreInformation {
prompt #"
{{ _.role("system") }}
You are a helpful assistant that manages deployments...
{{ _.role("user") }}
{{ thread }}
What should the next step be?
"#
}掌握自己 prompt 的关键好处:
- 完全控制:写明确的指令,没有黑盒抽象
- 测试和评估:像对待任何代码一样为 prompt 建测试
- 快速迭代:基于真实表现修改 prompt
- 透明:确切知道你的 agent 收到什么指令
- 角色 hack:利用支持非标准 user/assistant 角色用法的 API,做一些”模型 gaslighting”技巧
记住:你的 prompt 是应用逻辑和 LLM 之间的主要接口。
我不知道什么是最好的 prompt,但我知道你想要那种”什么都能试”的灵活度。
Factor 3 —— 掌握自己的 context window

你不一定需要用标准的 message 格式来给 LLM 传 context。
在任何时刻,你给 agent 里 LLM 的输入就是”到目前为止发生了什么,下一步是什么”
一切都是 context engineering。LLM 是无状态的函数,把输入转成输出。要拿最好的输出,你得给它最好的输入。
构造好 context 意味着:
- 你给模型的 prompt 和指令
- 你拿到的任何文档或外部数据(如 RAG)
- 任何过去的状态、工具调用、结果或其他历史
- 任何来自相关但分离的历史/对话的过往消息或事件(memory)
- 关于该输出什么样结构化数据的指令
标准格式 vs 自定义格式
大多数 LLM 客户端用基于 message 的标准格式:
[
{"role": "system", "content": "You are a helpful assistant..."},
{"role": "user", "content": "Can you deploy the backend?"},
{"role": "assistant", "content": null, "tool_calls": [{"id": "1", "name": "list_git_tags", "arguments": "{}"}]},
{"role": "tool", "name": "list_git_tags", "content": "{...}", "tool_call_id": "1"}
]这对大多数用例都很好,但如果你想真正榨干今天 LLM 的潜能,你需要把 context 以最 token-高效、最 attention-高效的方式喂进去。
替代方案是造你自己的 context 格式,优化你的用例。比如,你可以用自定义对象,把它们 pack/spread 进一个或多个 user/system/assistant/tool 消息里。
这是把整个 context window 装进一个 user message 的例子(用 XML 风格):
Here's everything that happened so far:
<slack_message>
From: @alex
Channel: #deployments
Text: Can you deploy the backend?
</slack_message>
<list_git_tags>
intent: "list_git_tags"
</list_git_tags>
<list_git_tags_result>
tags:
- name: "v1.2.3"
commit: "abc123"
date: "2024-03-15T10:00:00Z"
</list_git_tags_result>
what's the next step?掌握自己 context window 的关键好处:
- 信息密度:用最大化 LLM 理解的方式组织信息
- 错误处理:用帮 LLM 恢复的格式包含错误信息;考虑在错误解决后把它们从 context 隐藏
- 安全:控制传给 LLM 的信息,过滤敏感数据
- 灵活:随你学习什么有效来调整格式
- Token 效率:为 token 效率和 LLM 理解优化 context 格式
Context 包括:prompt、指令、RAG 文档、历史、工具调用、memory
记住:context window 是你跟 LLM 的主要接口。掌控你怎么组织和呈现信息,可以戏剧性地提升 agent 表现。
不只是我说
12-Factor agents 发布大约 2 个月后,“context engineering” 这个词开始流行。Karpathy 和 Tobi 都在 X 上谈论它。
🟢 译注:这是整套 12 条里最被引用的 Factor,也是 Karpathy 后来推动”context engineering”成为行业默认词的源头之一。如果你只读一条 Factor,就读这条。
Factor 4 —— 工具就是结构化输出
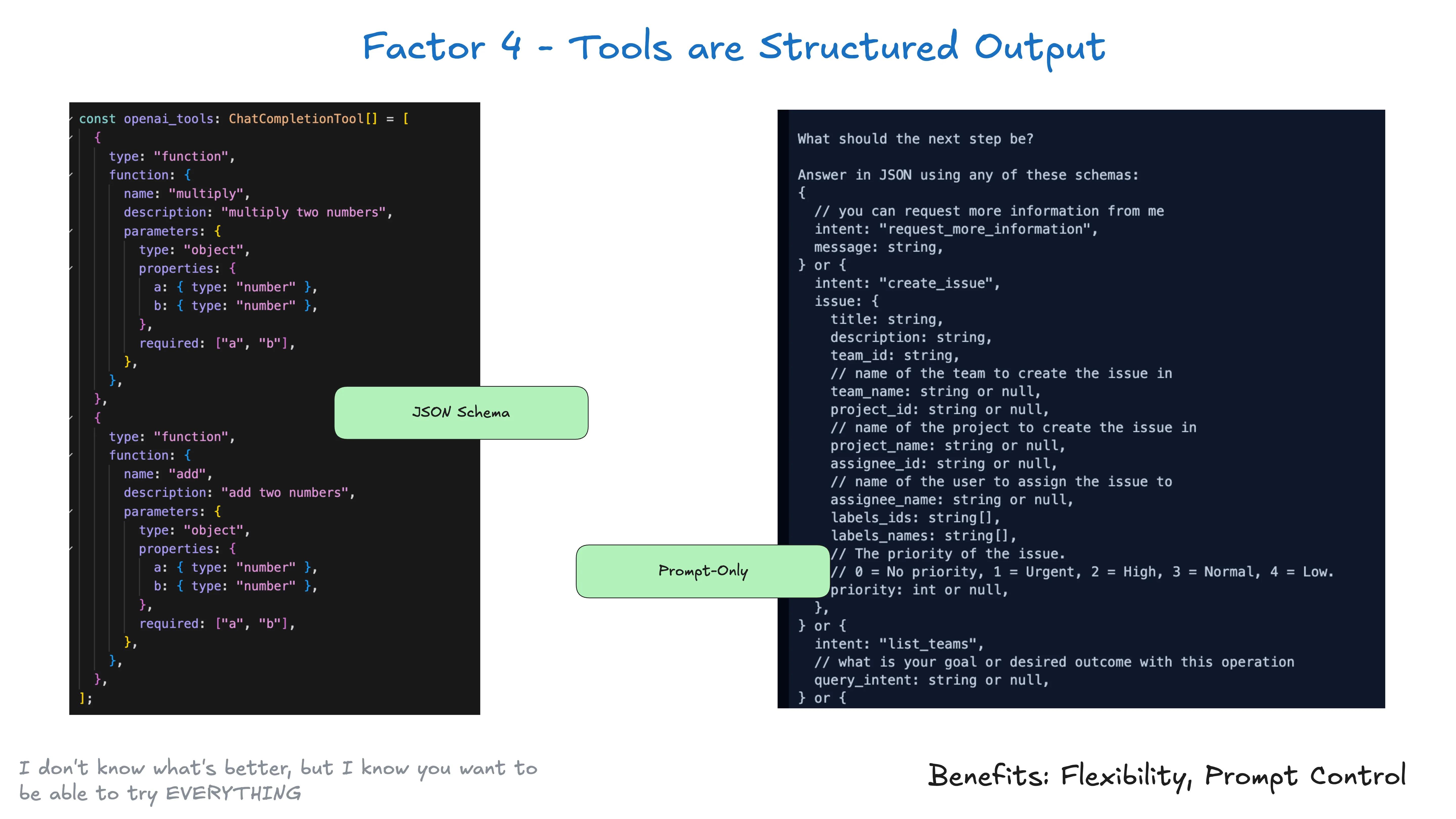
工具不需要复杂。它们核心就是从 LLM 来的结构化输出,触发确定性代码。
class CreateIssue:
intent: "create_issue"
issue: Issue
class SearchIssues:
intent: "search_issues"
query: str模式很简单:
- LLM 输出结构化 JSON
- 确定性代码执行合适的动作(比如调外部 API)
- 结果被捕获并喂回 context
这在 LLM 决策和你应用动作之间建了清晰的分隔。LLM 决定做什么,你的代码控制怎么做。LLM 调了一个工具,不意味着你必须每次都用同一种方式执行同一个对应函数。
🟢 译注:这一条祛魅了 tool calling。它不是魔法,只是”让 LLM 输出符合 schema 的字符串”。
Factor 5 —— 统一执行状态与业务状态
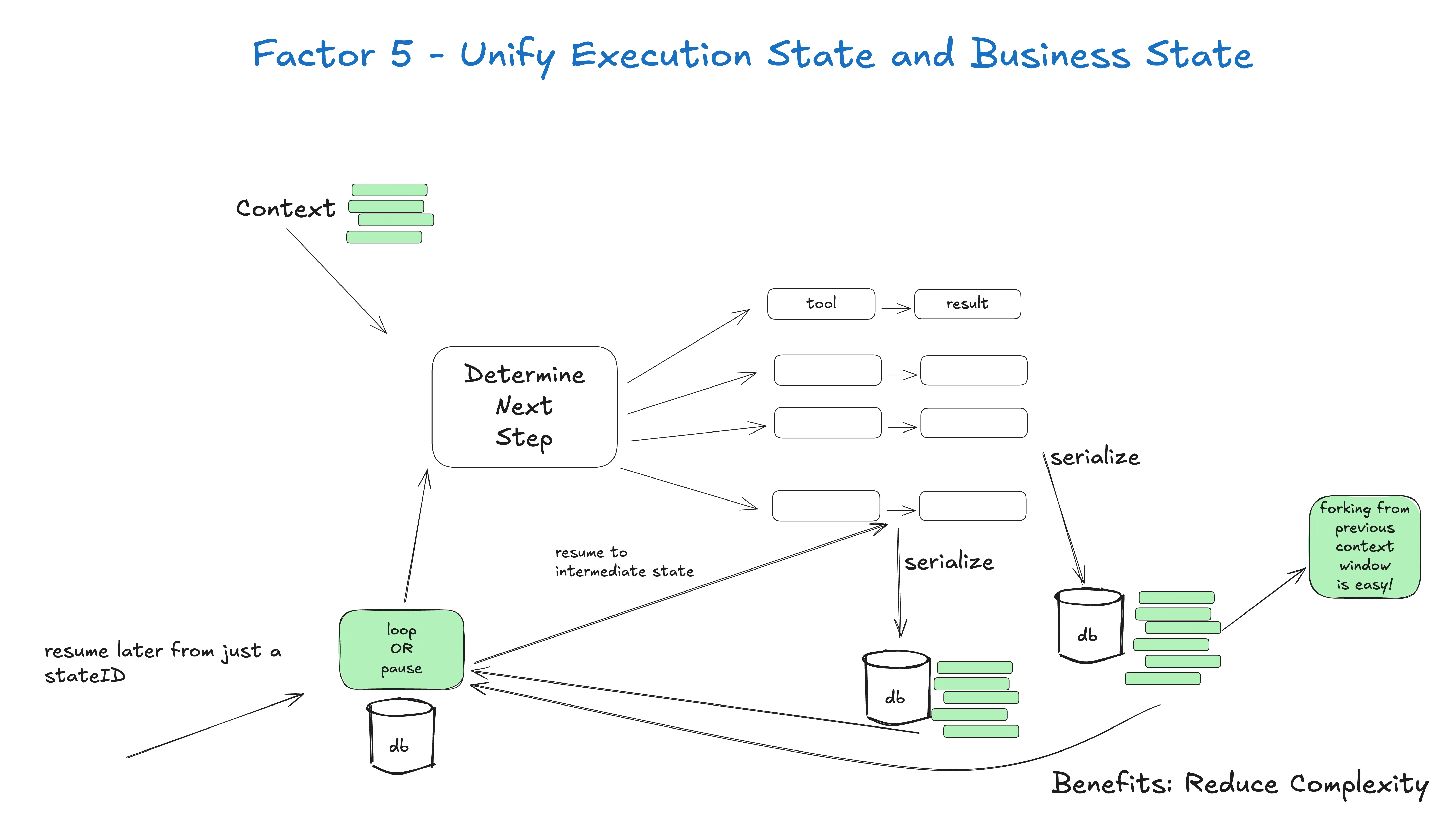
即使在 AI 之外,很多基础设施系统都试图分离”执行状态”和”业务状态”。对 AI 应用来说,这可能涉及复杂抽象来追踪当前步、下一步、等待状态、重试次数等。这种分离造成的复杂度可能值得,也可能对你的用例过度设计。
更清晰地讲:
- 执行状态:当前步、下一步、等待状态、重试次数等
- 业务状态:agent 工作流到目前为止发生了什么(比如 OpenAI 消息列表、工具调用和结果列表等)
如果可能,简化 —— 尽可能统一它们。
实际上,你可以工程化你的应用,让你能从 context window 推断所有执行状态。在很多情况下,执行状态(当前步、等待状态等)只是已发生事情的元数据。
好处:
- 简单:所有状态一个真相源
- 序列化:线程可轻易序列化/反序列化
- 调试:整个历史在一个地方可见
- 灵活:加新事件类型就能加新状态
- 恢复:从任何点加载线程就能恢复
- 分叉:复制线程的子集到新 context 就能分叉
- 人类接口和可观测性:把线程转成可读 markdown 或丰富的 Web UI 都很容易
Factor 6 —— 用简单 API 实现启动/暂停/恢复
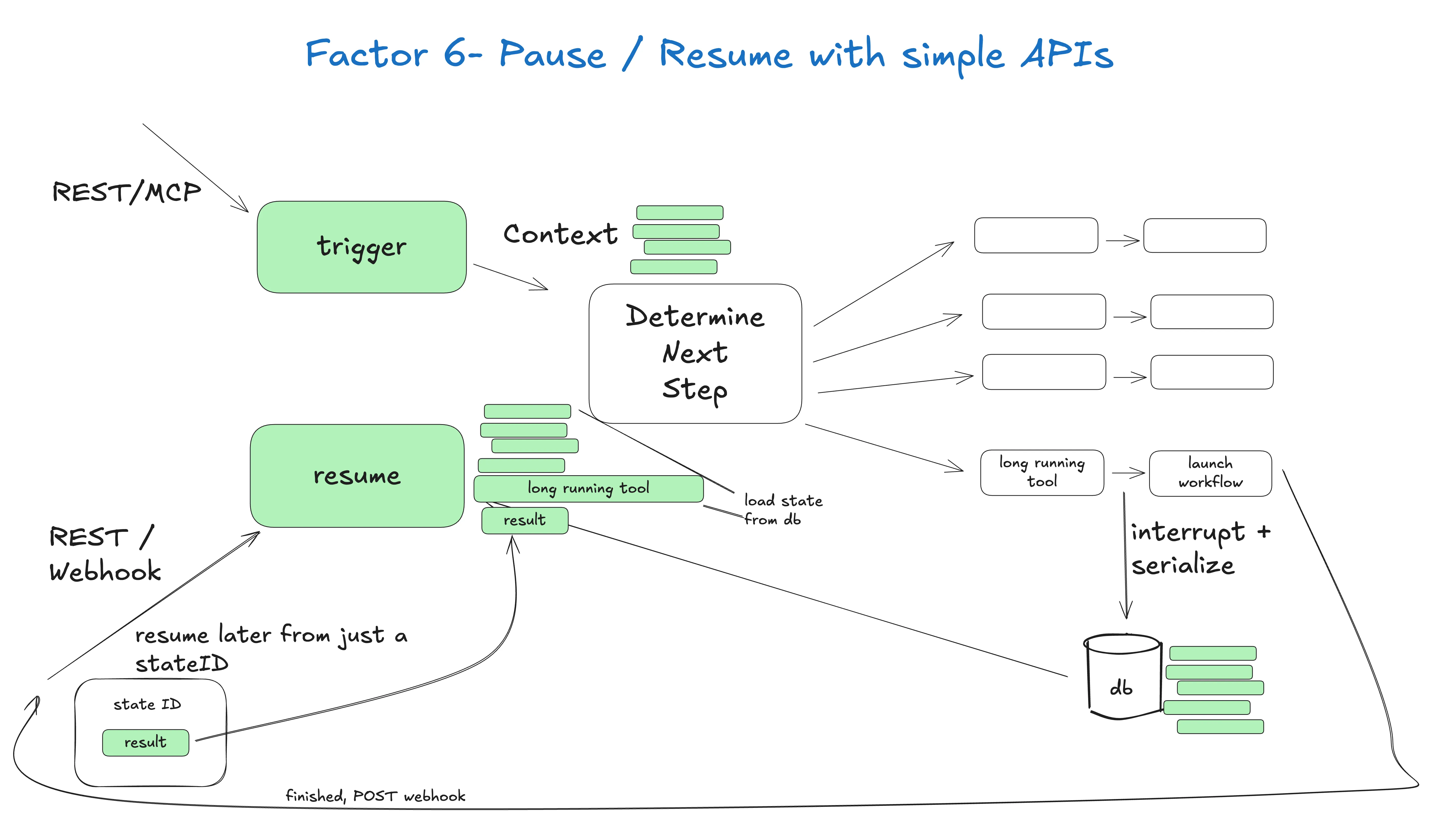
Agent 就是程序,我们对怎么启动、查询、恢复、停止它们有清晰预期。
- 启动应该简单:用户、应用、流水线、其它 agent,通过简单 API 启动
- 暂停应该被支持:遇到长时操作时 agent 应能被暂停
- 外部触发恢复:webhook 这种应该能让 agent 从暂停点恢复,不需要深度集成 agent 编排器
注意 —— 很多 AI 编排器允许暂停和恢复,但不允许在工具选择和工具执行之间暂停。这正是 Factor 7 和 Factor 11 要解决的核心间隙。
🟢 译注:这一条在 Armin 那篇里被反复印证 —— 不能在工具选择和工具执行之间暂停的 agent,无法做”高风险操作前的人工审批”,是生产 agent 的致命缺陷。
Factor 7 —— 用工具调用联系人

LLM API 默认依赖一个根本性、高赌注的 token 选择:返回纯文本,还是返回结构化数据?
你把很多权重压在那个第一个 token 的选择上。“东京的天气”那种情况,第一个 token 是 “the”;“fetch_weather” 那种,是某个特殊 token 标记 JSON 对象的开始。
你可能让 LLM 永远输出 JSON,然后用一些自然语言 token 声明意图(比如 request_human_input 或 done_for_now),反而拿到更好结果。
class RequestHumanInput:
intent: "request_human_input"
question: str
context: str
options: Options
if nextStep.intent == 'request_human_input':
thread.events.append({type: 'human_input_requested', data: nextStep})
thread_id = await save_state(thread)
await notify_human(nextStep, thread_id)
return # 中断循环,等响应后面你可能从 Slack/邮件/SMS 收到 webhook:
@app.post('/webhook')
def webhook(req):
thread = await load_state(req.body.threadId)
thread.events.push({type: 'response_from_human', data: req.body})
next_step = await determine_next_step(thread_to_prompt(thread))
...好处:
- 明确指令:不同类型的人类联系工具让 LLM 更具体
- 内循环 vs 外循环:启用 ChatGPT 风格之外的 agent 工作流,控制流和 context 初始化可以是
Agent → Human而不只是Human → Agent(想想 cron 或事件触发的 agent) - 多人接入:可以追踪和协调来自不同人类的输入
- 多 agent:简单抽象可扩展支持
Agent → Agent请求和响应 - 持久:配合 Factor 6 的 launch/pause/resume,你得到持久、可靠、可内省的多人工作流
🟢 译注:HumanLayer 的整个产品线都建在这条 Factor 上。“问人”不是特殊机制,就是另一个 tool。
Factor 8 —— 掌握自己的控制流
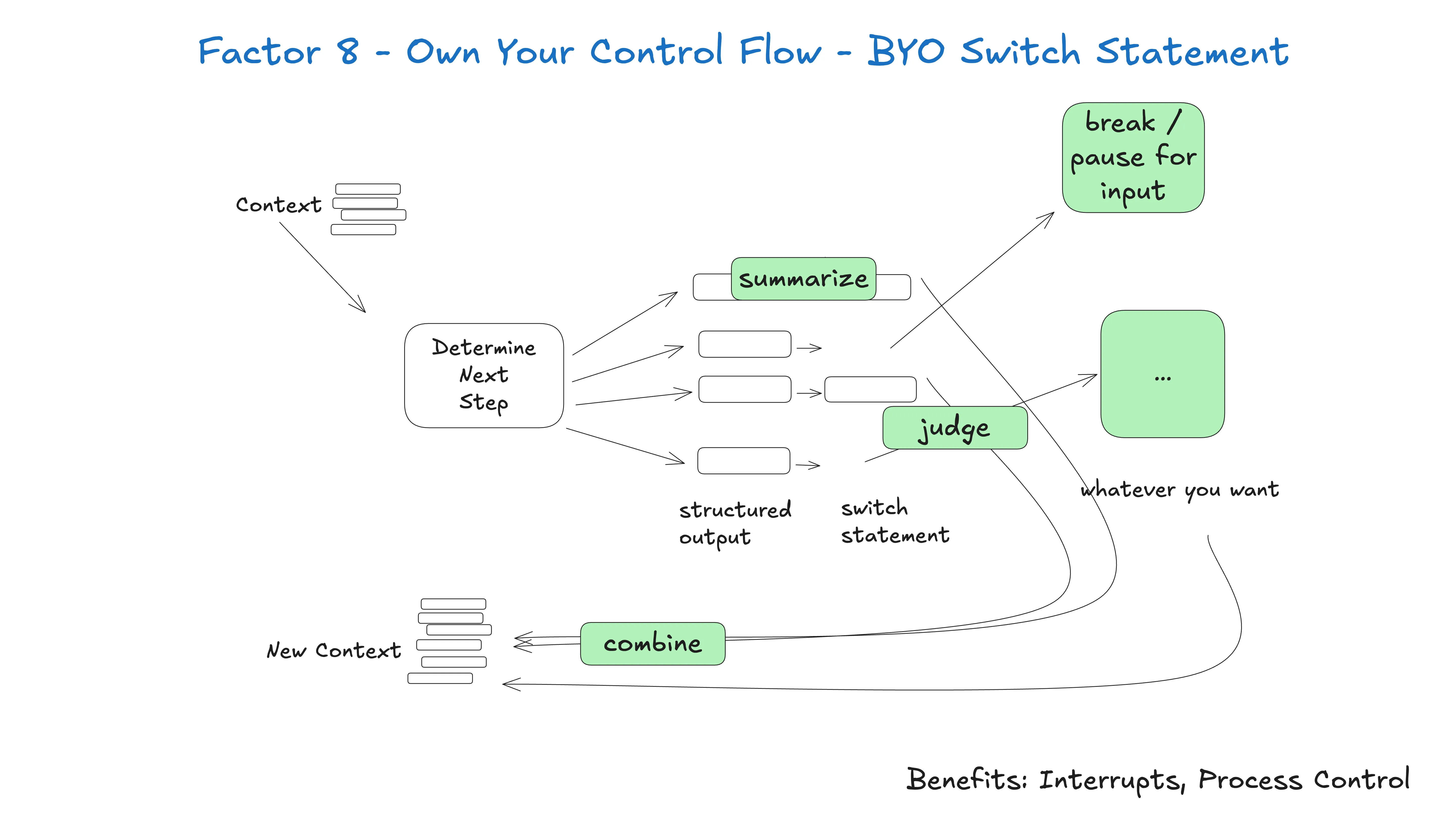
如果你掌握自己的控制流,你能做很多有意思的事。
为你具体用例造合适的控制结构。具体地,某些类型的工具调用可能要中断循环,等人或等长跑任务(比如训练流水线)。你可能还想加入自定义实现:
- 工具调用结果的总结或缓存
- LLM-as-judge 评估结构化输出
- context window 压缩或其它 memory 管理
- 日志、追踪、metrics
- 客户端限速
- 持久 sleep / pause / “等事件”
下面例子展示 3 种可能的控制流模式:
def handle_next_step(thread: Thread):
while True:
next_step = await determine_next_step(thread_to_prompt(thread))
if next_step.intent == 'request_clarification':
# 异步:中断循环,后面 webhook 来恢复
thread.events.append({...})
await send_message_to_human(next_step)
await db.save_thread(thread)
break
elif next_step.intent == 'fetch_open_issues':
# 同步:直接执行,把结果喂回 LLM
thread.events.append({...})
issues = await linear_client.issues()
thread.events.append({type: 'fetch_open_issues_result', data: issues})
continue
elif next_step.intent == 'create_issue':
# 高风险:中断,等人审批
thread.events.append({...})
await request_human_approval(next_step)
await db.save_thread(thread)
break示例 —— 我对每一个 AI 框架的头号功能请求是:我们必须能中断一个工作中的 agent,在工具选择和工具执行之间随时恢复。
没有这种粒度的可恢复性,你只能:
- 在
while...sleep里暂停任务,如果进程被打断就从头重启 - 限制 agent 只做低风险调用(研究、总结)
- 给 agent 大权限,YOLO 祈祷别搞砸
🟢 译注:Factor 8 跟 Factor 3 是 12-Factor 的灵魂双柱。这两条没做对,其它 10 条都救不了你。
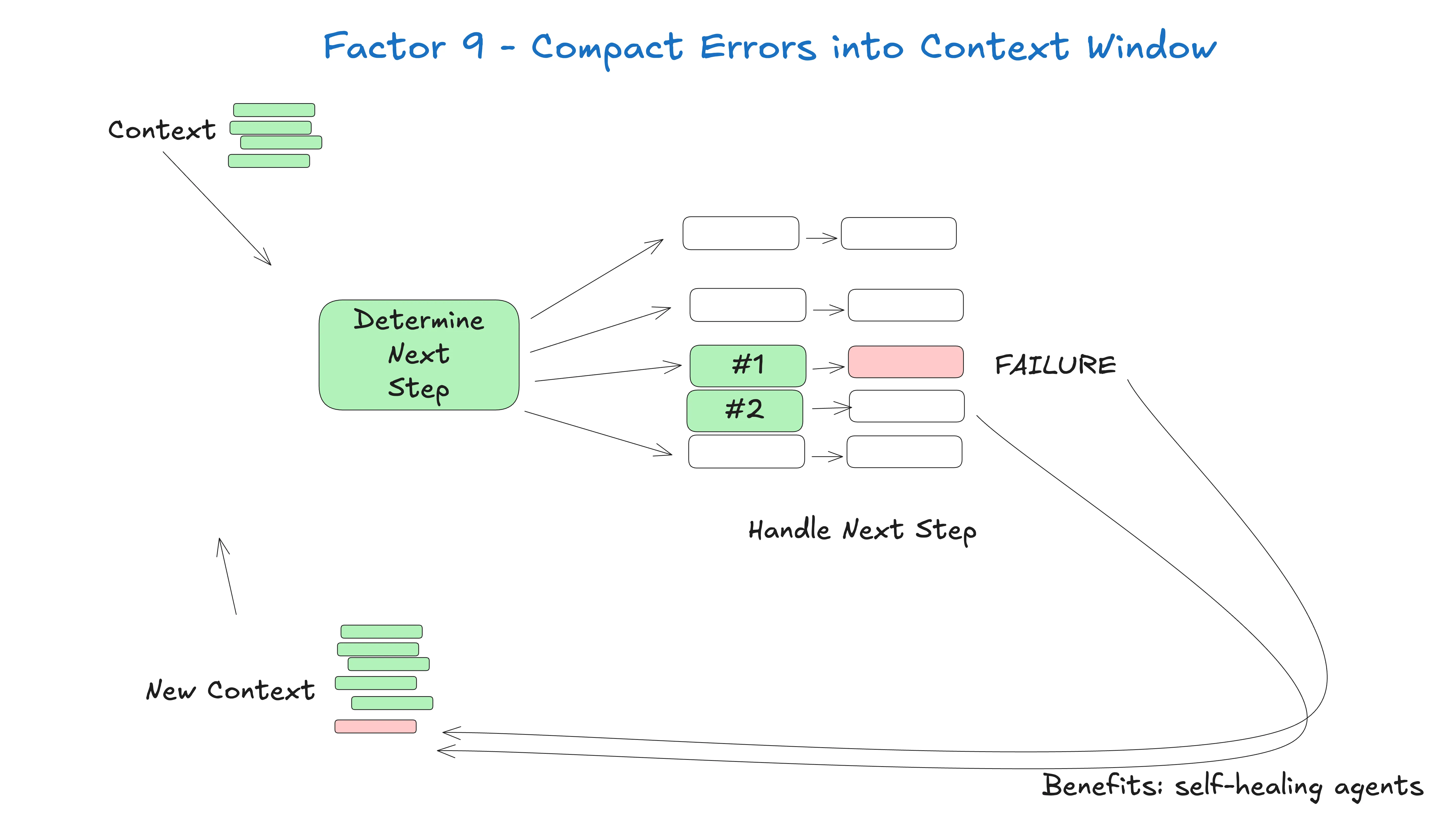
Factor 9 —— 把错误压缩进 context window
这条比较短,但值得提。agent 的好处之一是”自愈” —— 短任务里 LLM 调一个工具失败,好的 LLM 有不错的概率读懂错误信息或堆栈,在下一次工具调用里调整。
while True:
next_step = await determine_next_step(thread_to_prompt(thread))
thread["events"].append({"type": next_step.intent, "data": next_step})
try:
result = await handle_next_step(thread, next_step)
except Exception as e:
thread["events"].append({"type": 'error', "data": format_error(e)})
# 循环或恢复你可能想为单个工具调用加一个 errorCounter,限制到 ~3 次尝试:
consecutive_errors = 0
while True:
try:
result = await handle_next_step(thread, next_step)
consecutive_errors = 0
except Exception as e:
consecutive_errors += 1
if consecutive_errors < 3:
thread["events"].append({"type": 'error', "data": format_error(e)})
else:
break # 升级到人,或重置 context window如果做太多,agent 会开始打转,反复犯同样的错。这就是为什么 Factor 8(掌握控制流)和 Factor 3(掌握 context)的存在 —— 错误信息不要原样塞回 context,你应该完全重构它的呈现方式,移除以前的事件,做任何能让 agent 回到正轨的确定性的事。
但防止 error spin-out 的头号方式是 Factor 10 —— 小而专注的 agent。
Factor 10 —— 小而专注的 agent
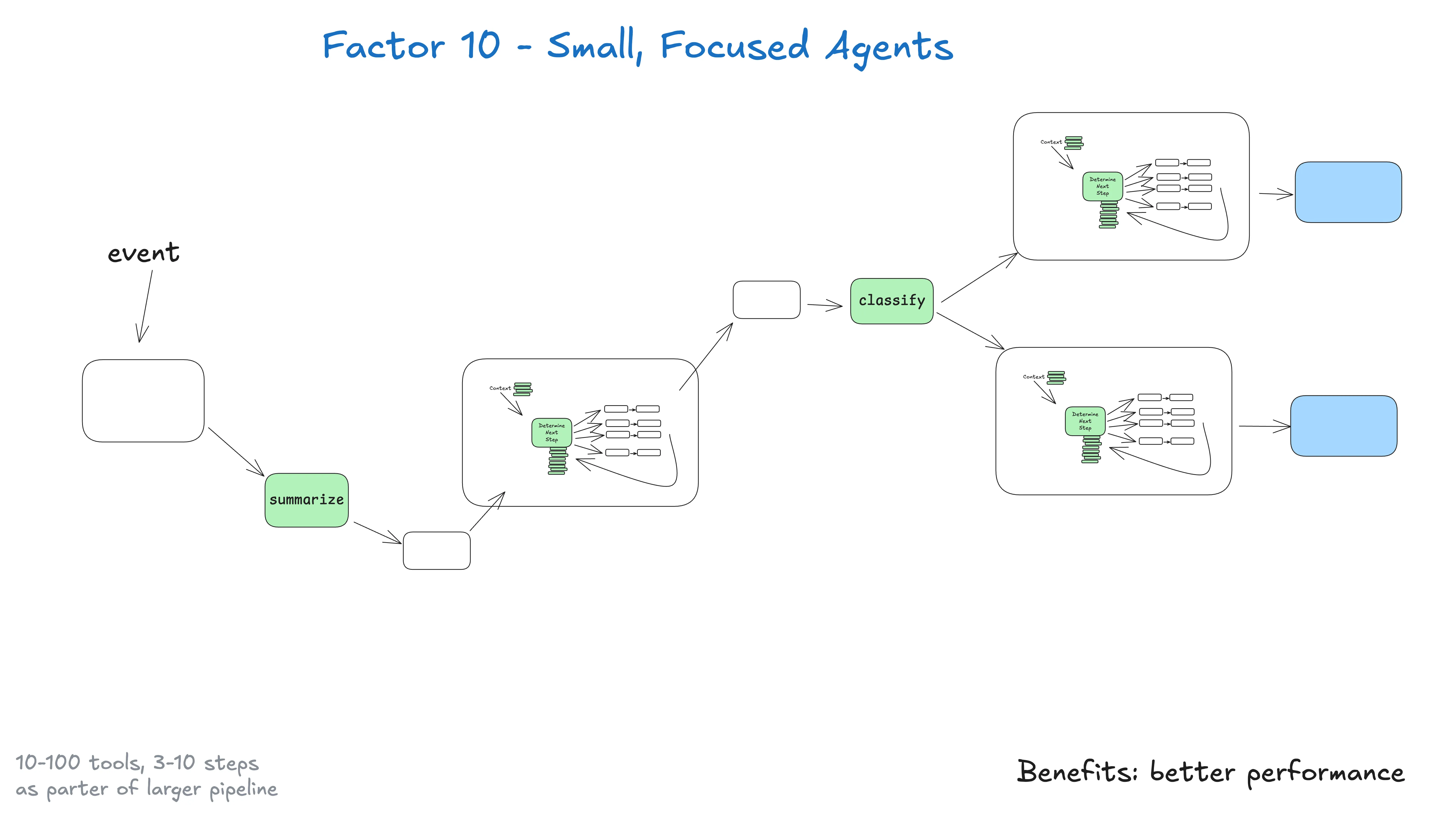
别造试图什么都做的单体 agent。造小而专注、把一件事做好的 agent。Agent 只是更大的、主要确定性的系统里的一个积木。
关键洞察是关于 LLM 的局限:任务越大越复杂,步骤越多,context window 越长。context 越长,LLM 越容易迷失或失焦。让 agent 聚焦在特定领域、3-10 步(最多 20 步),保持 context window 可管理、LLM 表现高。
Context 越长,LLM 越容易迷失或失焦
好处:
- 可管理 context:更小 context window 意味更好 LLM 表现
- 职责清晰:每个 agent 有清晰范围
- 更可靠:不容易在复杂工作流里迷失
- 更易测试:更易测试和验证特定功能
- 更易调试:更容易找问题、修问题
LLM 变聪明了还需要这条吗?
简单说:需要。LLM 改进时,可能自然能处理更长 context window,意味着处理更大 DAG 的更多部分。这种小而专注的方式让你今天就能拿到结果,同时给 LLM context window 变得更可靠时一个慢慢扩展 agent 范围的路径。
NotebookLM 团队的一句话总结得好:
我感觉,AI 建造里最有魔法的时刻,总是在我真的、真的、真的接近模型能力边缘的时候。
不管那个边界在哪,如果你能找到它并稳定地跨过它,你就能造出有魔法的体验。
Factor 11 —— 任何地方都能触发,在用户在的地方接住他们
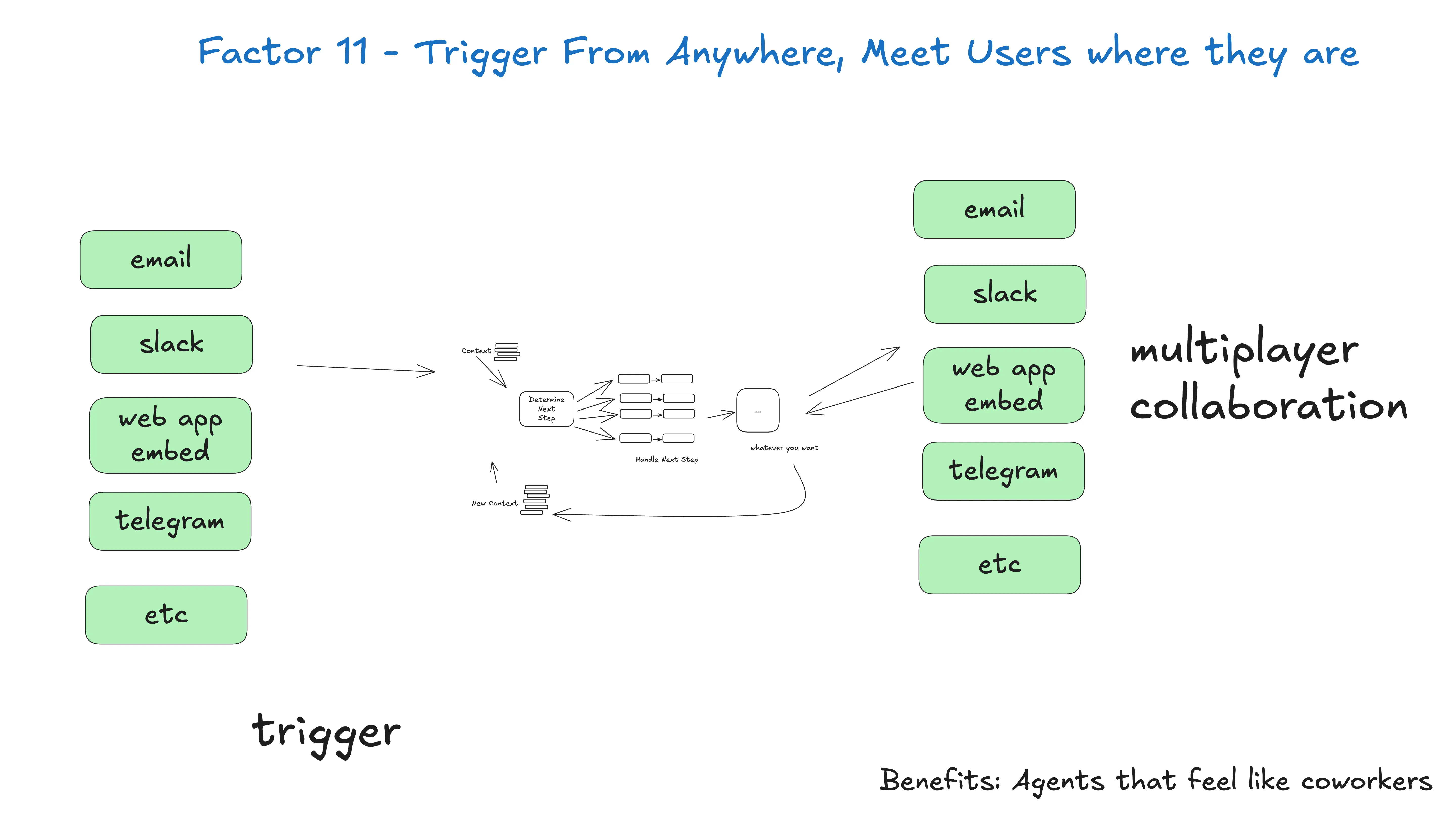
让用户能从 Slack、邮件、SMS 或任何渠道触发 agent。让 agent 通过同一渠道响应。
好处:
- 在用户在的地方接他们:让 AI 应用感觉像真人,或至少像数字同事
- 外循环 agent:让 agent 能被非人触发(事件、cron、故障)。它们可以工作 5、20、90 分钟,到达关键点时联系人求助、反馈或审批
- 高风险工具:如果你能快速把多种人拉进环路,你就能给 agent 高风险操作的权限(发外部邮件、改生产数据)。维持清晰标准给你审计能力和信心
Factor 12 —— 让 agent 变成无状态归约函数
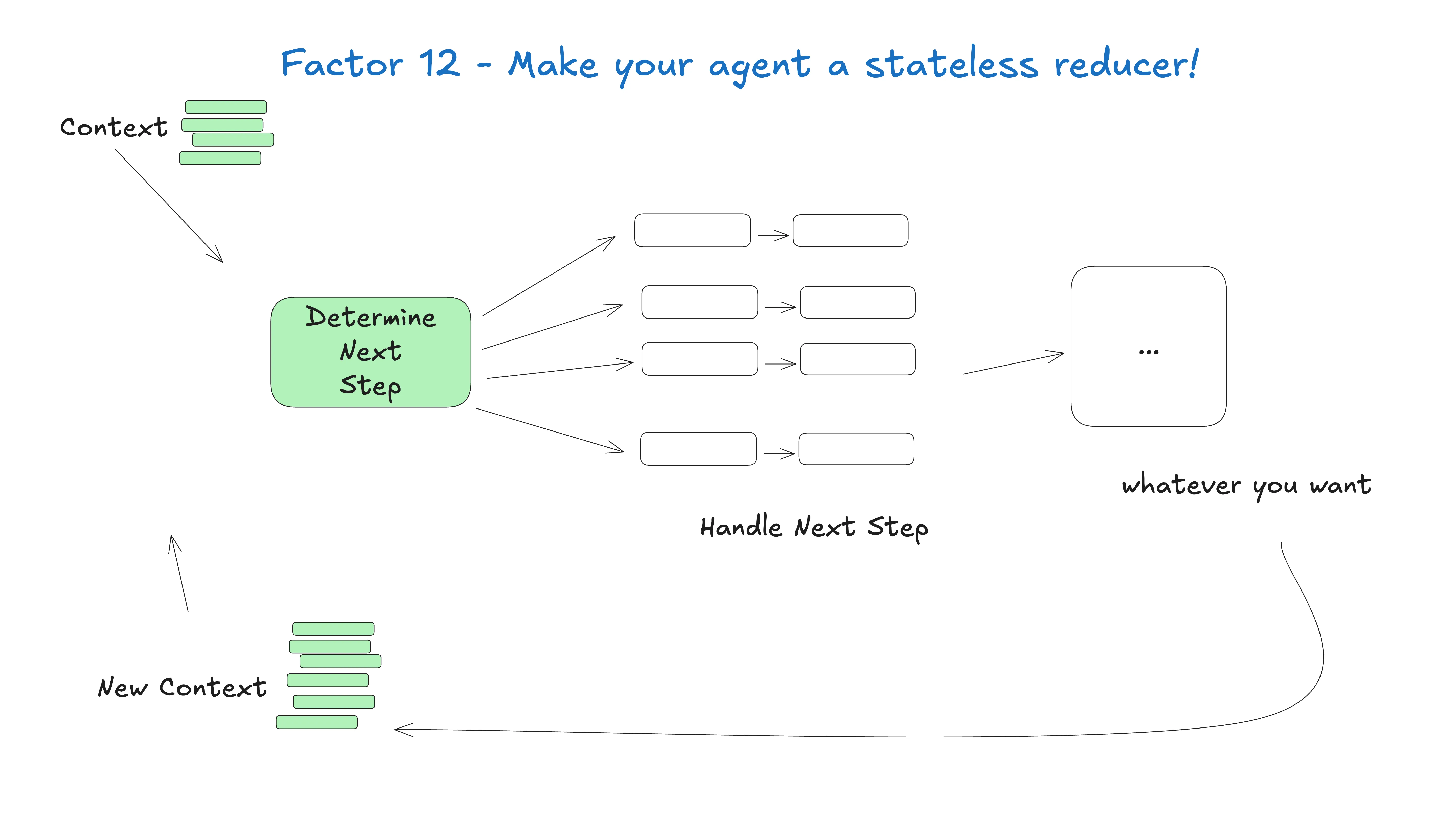
我们已经超过 1000 行 markdown 了。这一条主要是为了好玩。
把 agent 想成 foldl —— 一个无状态归约器,take 当前 state + 当前事件,return 下一个 state。所有 state 在外部,reducer(LLM)是无状态的。
🟢 译注:Factor 12 是函数式编程对 agent 工程的最大贡献。把 agent 想成 reducer,你就再也不会在 agent 内部存状态了 —— 这种架构可无限扩展。
致谢与版权
特别感谢 @iantbutler01、@tnm、@hellovai、@stantonk、@balanceiskey、@AdjectiveAllison、@pfbyjy、@a-churchill 和 SF MLOps 社区在初稿阶段给的反馈。
所有内容和图片用 CC BY-SA 4.0 协议。代码用 Apache 2.0 协议。
译者总评
如果你只从这篇带走 3 条:
- Factor 3:Own your context window —— 90% 生产 agent 失败的根因
- Factor 8:Own your control flow —— 不要把核心逻辑藏在框架黑盒里
- Factor 10:Small, focused agents —— 别建巨型 agent,建一堆小的拼起来
12 条原则的本质是一句话:Agent 是软件。当你把它当软件来工程化,你赢;当你把它当魔法 loop,你输。
🔗 调研来源(可校验)
见 03-dex-horthy-12-factor-agents.md 末尾的”调研来源”段落。本文与 03 互为对照。